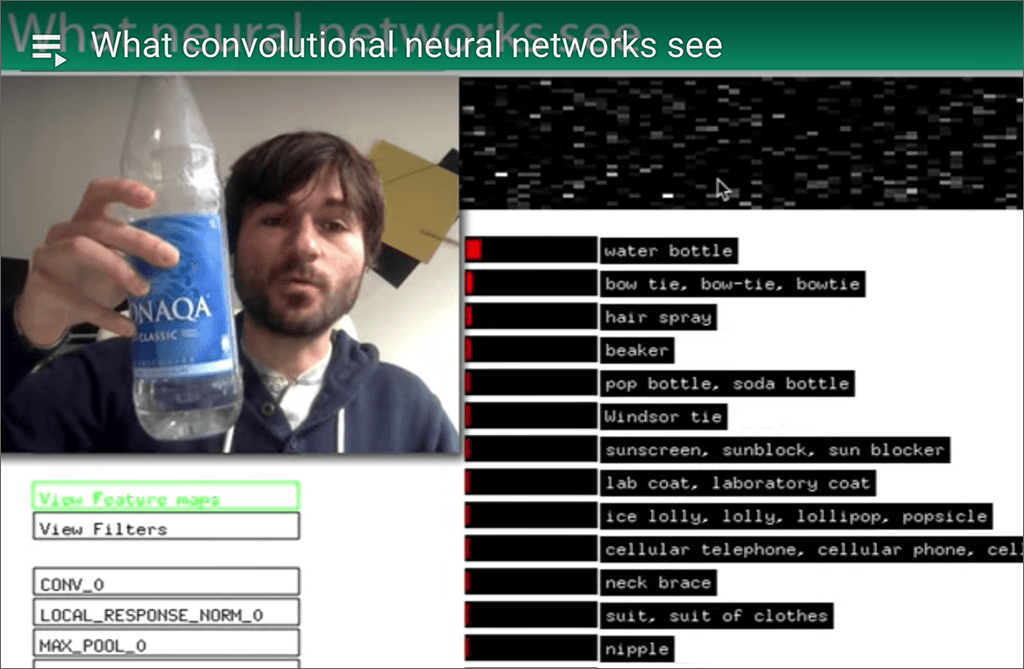
When I first read a description of how recurrent neural networks differ from other neural networks, I was all like, yeah, that’s cool. I looked at a diagram that had little loops drawn around the units in the hidden layer, and I thought I understood it.
As I thought more about it, though, I realized I didn’t understand how it could possibly do what the author said it did.
In many cases, the input to a recurrent neural net (RNN) is text (more accurately: a numeric representation of text). It might be a sentence, or a tweet, or an entire review of a restaurant or a movie. The output might tell us whether that text is positive or negative, hostile or benign, racist or not — depending on the application. So the system needs to “consider” the text as a whole. Word by word will not work. The meanings of words depend on the context in which we find them.
And yet, the text has to come in, as input, word by word. The recurrent action (the loops in the diagram) are the way the system “holds in memory” the words that have already come in. I thought I understood that — but then I didn’t.
Michael Nguyen’s excellent video (under 10 minutes!), above, was just what I needed. It is a beautiful explanation — and what’s more, he made a text version too: Illustrated Guide to Recurrent Neural Networks. It includes embedded animations, like the ones in the video.
In the video, Nguyen begins with a short list of the ways we are using the output from RNNs in our everyday lives. Like many of the videos I post here, this one doesn’t get into the math but instead focuses on the concepts.
If you can remember the idea of time steps, you will be able to remember how RNNs differ from other types of neural nets. The time steps are one-by-one inputs that are parts of a larger whole. For a sentence or longer text, each time step is a word. The order matters. Nguyen shows an animated example of movement to make the idea clear: we don’t know the direction of a moving dot unless we know where it’s been. One freeze-frame doesn’t tell us the whole story.
RNNs are helpful for “reading” any kind of data in a sequence. The hidden layer reads word 1, produces an output, and then returns it as a precursor to word 2. Word 2 comes in and is modified by that prior output. The output from word 2 loops back and serves as a precursor to word 3. This continues until a stop symbol is reached, signifying the end of the input sequence.
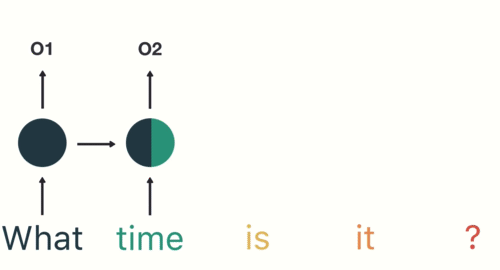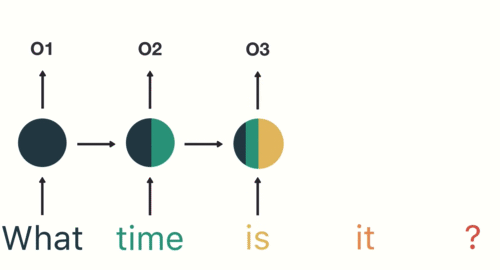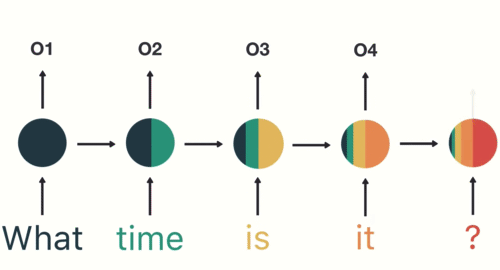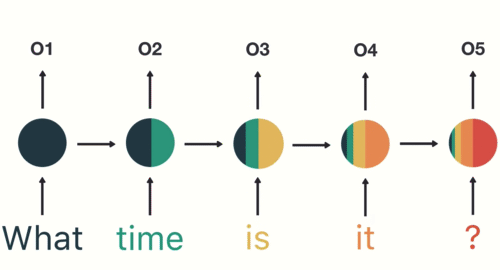
There’s a bit of a problem in that the longer the sequence, the less influence the earliest steps have on the current one. This led me down a long rabbit hole of learning about long short-term memory networks and gradient descent. I used this article and this video to help me with those.
At 6:23, Nguyen begins to explain the effects of back propagation on a deep feed-forward neural network (not an RNN). This was very helpful! He defines the gradient as “a value used to adjust the network’s internal weights, allowing the network to learn.”
At 8:35, he explains long short-term memory networks (LSTMs) and gated recurrent units (GRUs). To grossly simplify, these address the problem noted above by essentially learning what is important to keep and what can be thrown away. For example, in the animation above, what and time are the most important; is and it can be thrown away.
So an RNN will be used for shorter sequences, and for longer sequences, LSTMs or GRUs will be used. Any of these will loop back within the hidden layer to obtain a value for the complete sequence before outputting a prediction — a value.

AI in Media and Society by Mindy McAdams is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Include the author’s name (Mindy McAdams) and a link to the original post in any reuse of this content.
.