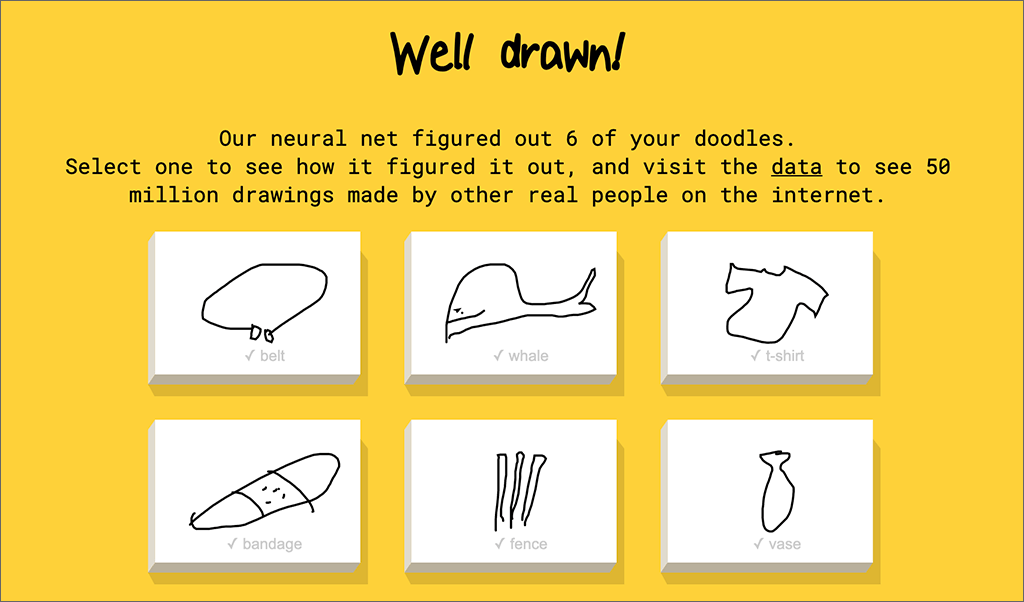
For Friday AI Fun, let’s look at an oldie but goodie: Google’s Quick, Draw!
You are given a word, such as whale, or bandage, and then you need to draw that in 20 seconds or less.
Screenshot 1 from Google’s Quick, Draw!
Screenshot 2 from Google’s Quick, Draw!
Thanks to this game, Google has labeled data for 50 million drawings made by humans. The drawings “taught” the system what people draw to represent those words. Now the system uses that “knowledge” to tell you what you are drawing — really fast! Often it identifies your subject before you finish.
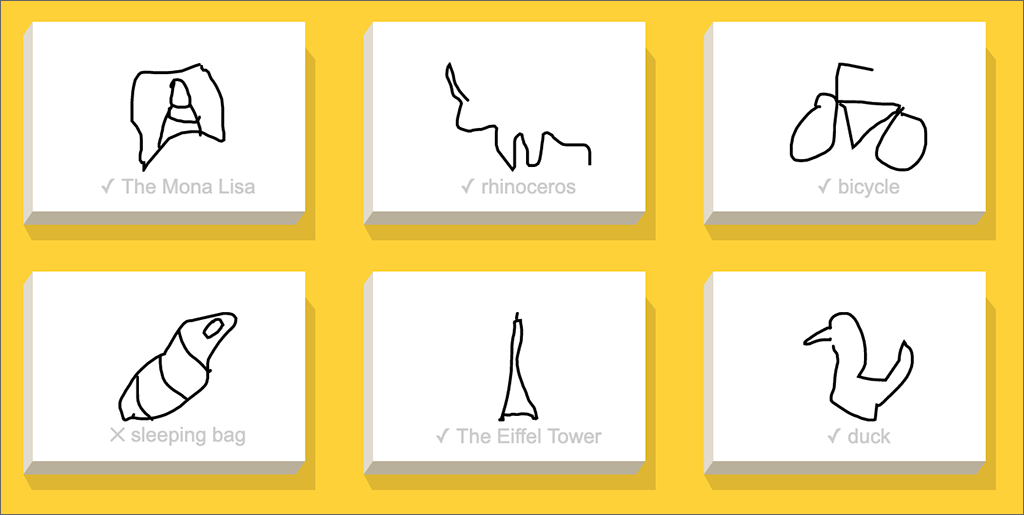
It is possible to stump the system, even though you’re trying to draw what it asked for. My drawing of a sleeping bag is apparently an outlier. My drawings of the Mona Lisa and a rhinoceros were good enough — although I doubt any human would have named them as such!
Screenshot 3 from Google’s Quick, Draw!
Google’s AI thought my sleeping bag might be a shoe, or a steak, or a wine bottle.
Screenshot 4 from Google’s Quick, Draw!
The system has “learned” to identify only 345 specific things. These are called its categories.
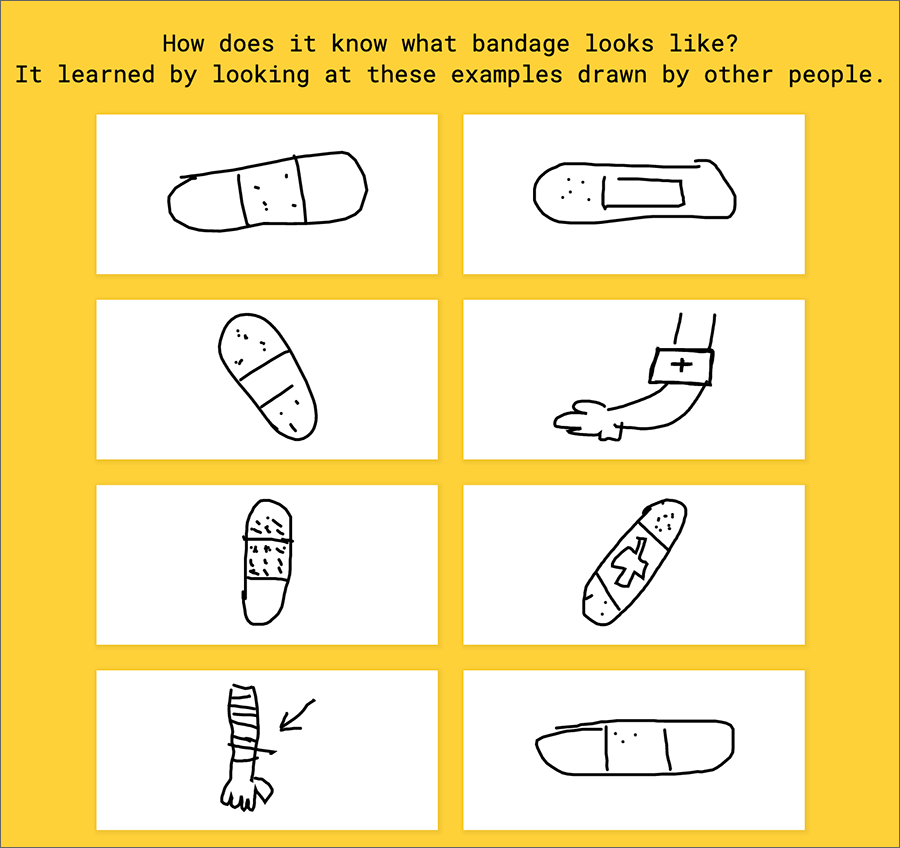
You can look at the data the system has stored — for example, here are a lot of drawings of beard.
Screenshot 5 from Google’s Quick, Draw!
You can download the complete data (images, labels) from GitHub. You can also install a Python library to explore the data and retrieve random images from a given category.
On Fridays I try to find something to write about that’s a little less heavy than explanations of neural networks and examinations of embedded biases in AI systems. I call it Friday AI Fun.
The BBC recently wrote about a mobile app that uses AI to help you concoct a meal from the ingredients you already have at home. Plant Jammer is available for both iOS and Android, and it doesn’t merely take your ingredients and find an existing recipe for you — it actually creates a new recipe.
According to BBC journalist Nell Mackenzie, the results are not always delicious. She made some veggie burgers that came out tasting like oatmeal.
I was interested in how the app uses AI, and this is what I found: The team behind Plant Jammer consists of 15 chefs and data scientists, based in Copenhagen, Denmark. They admit that “AI is only a fraction” of what powers the app, framing that as a positive because the app incorporates “gastronomical learnings from chefs.”
The app includes multiple databases, including one of complete recipes. An aspect of the AI is a recommender system, which they compare to Netflix’s. As Plant Jammer learns more about you, it will improve at creating recipes you like, based on “people like you.”
“We asked the chefs which ingredients are umami, and how umami they are. This part reflects the ‘human intelligence’ we used to build our system, a great ‘engine’ that has led to very interesting findings.”
—Michael Haase, CEO, Plant Jammer
My searches led me to an interview with Michael Haase, Plant Jammer’s CEO, in which he described the “gastro-wheel” feature in the app. The wheel encourages you to find balance in your ingredients among a base, something fresh, umami, crunch, sweet-spicy-bitter, and something that ties the ingredients together in harmony.
I’ve downloaded the app but, unlike Mackenzie, I haven’t been brave enough yet to let it create a recipe for me. Exploring some of the recommended recipes in the app, I did find the ability to select any ingredient and instantly see substitutions for it — that could come in handy!
Mackenzie’s article for the BBC also describes other AI–powered food and beverage successes, such as media agency Tiny Giant using AI to help clients “find new combinations of flavors for cupcakes and cocktails.”
MIT has a cool and easy-to-play game (okay, not really a game, but like a game) in which you get to choose what a self-driving car would do when facing an imminent crash situation.
Above: Results from one round of playing the MoralMachine
At the end of one round, you get to see how your moral choices measure up to those of other people who have played. Note that all the drawings of people in the game have distinct meanings. People inside the car are also represented. Try it yourself here.
It is often discussed how the split-second decision affecting who lives, who dies is one of the most difficult aspects of training an autonomous vehicle.
Imagine this scenario:
“The car is programmed to sacrifice the driver and the occupants to preserve the lives of bystanders. Would you get into that car with your child?”
—Meredith Broussard, The Atlantic, 2018
In a 2018 article, Self-Driving Cars Still Don’t Know How to See, data journalist and professor Meredith Broussard tackled this question head-on. We find that the way the question is asked elicits different answers. If you say the driver might die, or be injured, if a child in the street is saved, people tend to respond: Save the child! But if someone says, “You are the driver,” the response tends to be: Save me.
You can see the conundrum. When programming the responses into the self-driving car, there’s not a lot of room for fine-grained moral reasoning. The car is going to decide in terms of (a) Is a crash is imminent? (b) What options exist? (c) Does any option endanger the car’s occupants? (d) Does any option endanger other humans?
In previous posts, I’ve written a little about the weights and probability calculations used in AI algorithms. For the machine, this all comes down to math. If (a) is True, then what options are possible? Each option has a weight. The largest weight wins. The prediction of the “best outcome” is based on probabilities.
For Friday AI Fun, I’m sharing one of the first videos I ever watched about artificial intelligence. It’s a 10-minute TED Talk by Janelle Shane, and it’s actually pretty funny. I do mean “funny ha-ha.”
I’m not wild about the ice-cream-flavors example she starts out with, because what does an AI know about ice cream, anyway? It’s got no tongue. It’s got no taste buds.
But starting at 2:07, she shows illustrations and animations of what an AI does in a simulation when it is instructed to go from point A to point B. For a robot with legs, you can imagine it walking, yes? Well, watch the video to see what really happens.
This brings up something I’ve only recently begun to appreciate: The results of an AI doing something may be entirely satisfactory — but the manner in which it produces those results is very unlike the way a human would do it. With both machine vision and game playing, I’ve seen how utterly un-human the hidden processes are. This doesn’t scare me, but it does make me wonder about how our human future will change as we rely more on these un-human ways of solving problems.
“When you’re working with AI, it’s less like working with another human and a lot more like working with some kind of weird force of nature.”
—Janelle Shane
At 6:23 in the video, Shane shows another example that I really love. It shows the attributes (in a photo) that an image recognition system decided to use when identifying a particular species of fish. You or I would look at the tail, the fins, the head — yes? Check out what the AI looks for.
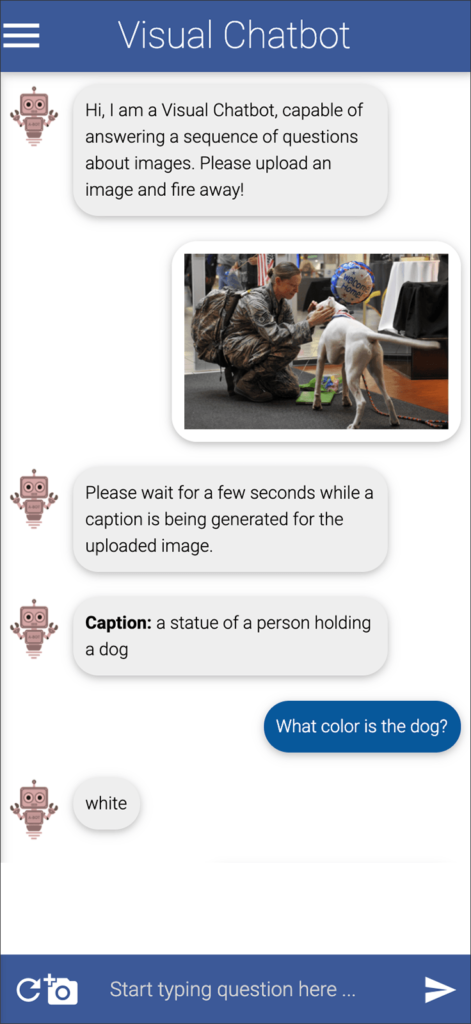
To see for yourself the product, or end results, of an AI system, check out the Visual Chatbot online. It’s free. It’s fun.
This app invites you to upload any image of your choice. It then generates a caption for that image. As you see above, the caption is not always 100 percent accurate. Yes, there is a dog in the photo, but there is no statue. There is a live person, who happens to be a soldier and a woman.
You can then have a conversation about the photo with the chatbot. The chatbot’s answer to my first question, “What color is the dog?”, was spot-on. Further questions, however, reveal limits that persist in most of today’s image-recognition systems.
The chat is still pretty awesome, though.
U.S. Department of Defense photo, 2015 (public domain)
The image appears in chapter 4 of in Artificial Intelligence: A Guide for Thinking Humans, where author Melanie Mitchell uses it to discuss the complexity that we humans can perceive instantly in an image, but which machines are still incapable of “seeing.”
In spite of the mistakes the chatbot makes in its answers to questions about this image, it serves as a nice demonstration of how today’s chatbots do not need to follow a set script. Earlier chatbots were programmed with rules that stepped through a tree or flowchart of choices — if the human’s question contains x, then reply with y.
You can see more info about Visual Dialog if you’re curious about what the Visual Chatbot entails in terms of data, model, and/or code.
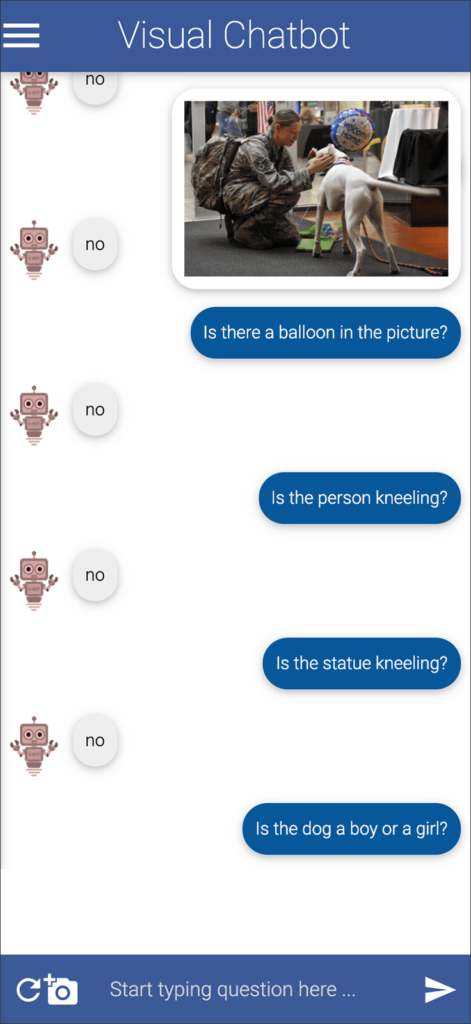
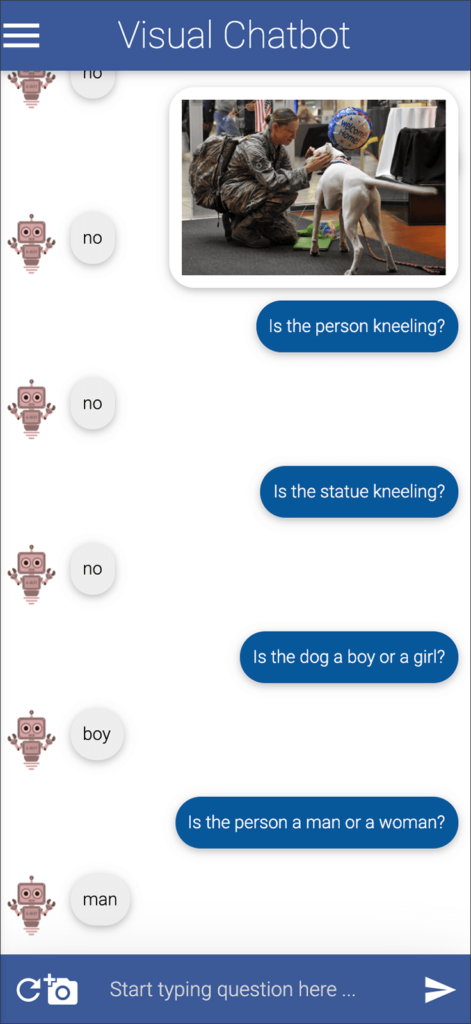
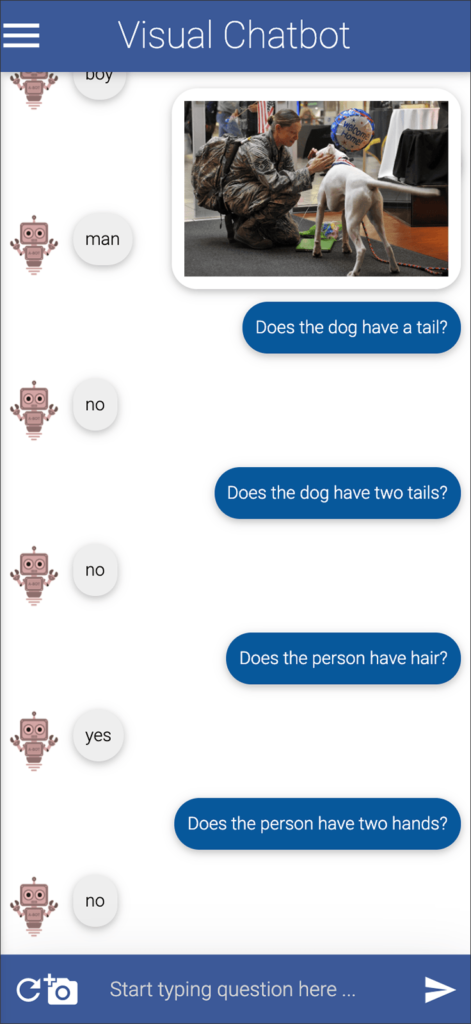
Below you can see some more questions I asked, with the answers from Visual Chatbot.
Some of my favorite wrong answers are on the last two screens. Note, you can ask questions that are not answered with only yes or no.
Think of a robot. Do you picture a human-looking construct? Does it have a human-like face? Does it have two legs and two arms? Does it have a head? Does it walk?
It’s easy to assume that a robot that walks across a room and picks something up has AI operating inside it. What’s often obscured in viral videos is how much a human controller is directing the actions of the robot.
I am a gigantic fan of the Spot videos from Boston Dynamics. Spot is not the only robot the company makes, but for me it is the most interesting. The video above is only 2 minutes long, and if you’ve never seen Spot in action, it will blow your mind.
But how much “intelligence” is built into Spot?
The answer lies in between “very little” and “Spot is fully autonomous.” To be clear, Spot is not autonomous. You can’t just take him out of the box, turn him on, and say, “Spot, fetch that red object over there.” (I’m not sure Spot can be trained to respond to voice commands at all. But maybe?) Voice commands aside, though, Spot can be programmed to perform certain tasks in certain ways and to walk from one given location to another.
This need for additional programming doesn’t mean that Spot lacks AI, and I think Spot provides a nice opportunity to think about rule-based programming and the more flexible reinforcement-learning type of AI.
This 20-minute video from Adam Savage (of MythBusters fame) gives us a look behind the scenes that clarifies how much of what we see in a video about a robot is caused by a human operator with a joystick in hand. If you pay attention, though, you’ll hear Savage point out what Spot can do that is outside the human’s commands.
Two points in particular stand out for me. The first is that when Spot falls over, or is upside-down, he “knows” how to make himself get right-side-up again. The human doesn’t need to tell Spot he’s upside-down. Spot’s programming recognizes his inoperable position and corrects it. Watching him move his four slender legs to do so, I feel slightly creeped out. I’m also awed by it.
Given the many incorrect positions in which Spot might land, there’s no way to program this get-right-side-up procedure using set, spelled-out rules. Spot must be able to use estimations in this process — just like AlphaGo did when playing a human Go master.
The second point, which Savage demonstrates explicitly, is accounting for non-standard terrain. One of the practical uses for a robot would be to send it somewhere a human cannot safely go, such as inside a bombed-out building — which would require the robot to walk over heaps of rubble and avoid craters. The human operator doesn’t need to tell Spot anything about craters or obstacles. The instruction is “Go to this location,” and Spot’s AI figures out how to go up or down stairs or place its feet between or on uneven surfaces.
The final idea to think about here is how the training of a robot’s AI takes place. Reinforcement learning requires many, many iterations, or attempts. Possibly millions. Possibly more than that. It would take lifetimes to run through all those training episodes with an actual, physical robot.
So, simulations. Here again we see how super-fast computer hardware, with multiple processes running in parallel, must exist for this work to be done. Before Spot — the actual robot — could be tested, he existed as a virtual system inside a machine, learning over nearly endless iterations how not to fall down — and when he did fall, how to stand back up.