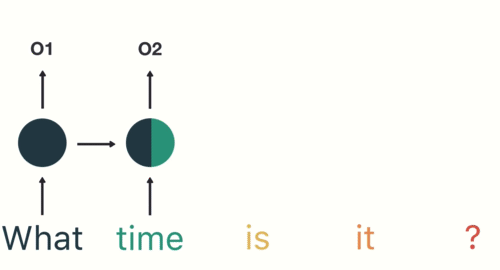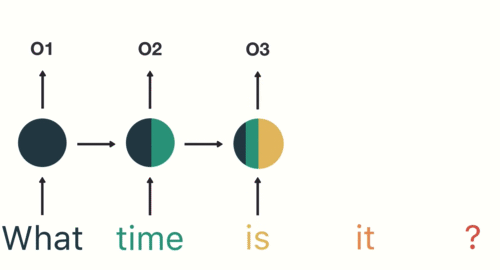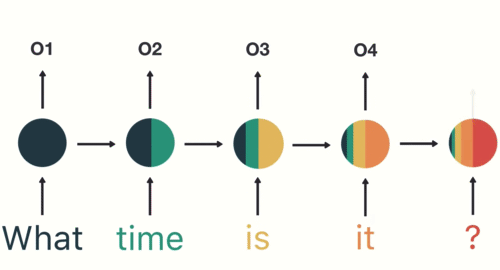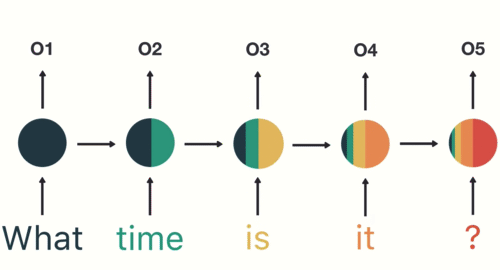
I was catching up today on a couple of new-ish developments in reinforcement learning/game-playing AI models.
Meta (which, we always need to note, is the parent company of Facebook) apparently has an entire team of researchers devoted to training an AI system to play Diplomacy, a war-strategy board game. Unlike in chess or Go, a player in Diplomacy must collaborate with others to succeed. Meta’s program, named Cicero, has passed the bar, as explained in a Gizmodo article from November 2022.
“Players are constantly interacting with each other and each round begins with a series of pre-round negotiations. Crucially, Diplomacy players may attempt to deceive others and may also think the AI is lying. Researchers said Diplomacy is particularly challenging because it requires building trust with others, ‘in an environment that encourages players to not trust anyone,’” according to the article.
We can see the implications for collaborations between humans and AI outside of playing games — but I’m not in love with the idea that the researchers are helping Cicero learn how to gain trust while intentionally working to deceive humans. Of course, Cicero incorporates a large language model (R2C2, further trained on the WebDiplomacy dataset) for NLP tasks; see figures 2 and 3 in the Science article linked below. “Each message in the dialogue training dataset was annotated” to indicate its intent; the dataset contained “12,901,662 messages exchanged between players.”
Cicero was not identified as an AI construct while playing in online games with unsuspecting humans. It “apparently ‘passed as a human player,’ in 40 games of Diplomacy with 82 unique players.” It “ranked in the top 10% of players who played more than one game.”
Meanwhile, DeepMind was busy conquering another strategy board game, Stratego, with a new AI model named DeepNash. Unlike Diplomacy, Stratego is a two-player game, and unlike chess and Go, the value of each of your opponent’s pieces is unknown to you — you see where each piece is, but its identifying symbol faces away from you, like cards held close to the vest. DeepNash was trained on self-play (5.5 billion games) and does not search the game tree. Playing against humans online, it ascended to the rank of third among all Stratego players on the platform — after 50 matches.
Apparently the key to winning at Stratego is finding a Nash equilibrium, which I read about at Investopedia, which says: “There is not a specific formula to calculate Nash equilibrium. It can be determined by modeling out different scenarios within a given game to determine the payoff of each strategy and which would be the optimal strategy to choose.”
Yesterday I summarized the first two articles in a series about algorithms and AI by Hayden Field, a technology journalist at Morning Brew. Today I’ll finish out the series.
The third article, This Powerful AI Technique Led to Clashes at Google and Fierce Debate in Tech. Here’s Why, explores the basis of the volatile situation around the firing of Timnit Gebru and later Margaret Mitchell from Google’s Ethical AI unit earlier this year. Both women are highly respected and experienced AI researchers. Mitchell founded the team in 2017.
“Models this big require an unthinkable amount of data; the entirety of English-language Wikipedia makes up just 0.6% of GPT-3’s training data.”
—”This Powerful AI Technique Led to Clashes at Google and Fierce Debate in Tech. Here’s Why”
The Morning Brew article sums up the very recent and very big improvements in large language models that have come about thanks to new algorithms and faster computer hardware (GPUs running in parallel). It highlights BERT, “the model that now underpins Google Search,” which came out of the research that resulted in the first Transformer. A good at-the-time article about GPT-3’s release was published in July 2020 in MIT’s Technology Review: “OpenAI first described GPT-3 in a research paper published in May [2020].”
One point being — Google fired Timnit Gebru very soon after news and discussion of large language models (GPT-3 especially, but remember Google’s investment in BERT too) ramped up — way up. Her criticism of a previously obscure AI technology (not obscure among NLP researchers, but in the wider world) might have been seen as increasingly inconvenient for Google. Morning Brew summarizes the criticism (not attributed to Gebru): “Because large language models often scrape data from most of the internet, racism, sexism, homophobia, and other toxic content inevitably filter in.”
“Once the barrier to create AI tools and generate text is lower, people could just use it to create misinformation at scale, and having that data coupled with certain other platforms can just be a very disastrous situation.”
—Sandhini Agarwal, AI policy researcher, OpenAi
The Morning Brew article goes well beyond Google’s dismissal of Gebru and Mitchell, bringing in a lot of clear, easy-to-understand explanation of what large language models require (for example, significant energy resources), what they’re being used for, and even the English-centric nature of such models — lacking a gigantic corpus of digitized text in a given human language, you can’t create a large model in that language.
The turmoil in Google’s Ethical AI unit is covered in more detail in this May 2021 article, also by Hayden Field.
It’s easy to find articles that discuss “scary things GPT-3 can do and does” and especially the bias issues; it’s much harder to find information about some of the other aspects covered here. It’s also not just about GPT-3. I appreciated insights from an interview with Emily M. Bender, first author on the “Stochastic Parrots” article. I also liked the explicit statement that many useful NLP tasks can be done well without a large language model. In smaller datasets, finding and accounting for toxic content can be more manageable.
“Do we need this at all? What’s the actual value proposition of the technology? … Who is paying the environmental price for us doing this, and is this fair?”
—Emily M. Bender, professor and director, Professional MS in Computational Linguistics, University of Washington
An AI system’s ability to generalize — to transfer learning from one domain to another — is still a wide-open frontier, according to Mark Riedl, a computer science professor at Georgia Tech. This is something I remind my students of over and over — what’s called “general intelligence” is still a long way off for artificial intelligence. Riedl works on aspects of storytelling to test whether an AI system is able to “make something new” out of what it has ingested.
Saška Mojsilović, head of Trusted AI Foundations at IBM Research, made a similar point — and also emphasized that “narrow AI” (which is all the AI we’ve ever had, up to now and for the foreseeable future) is not nothing.
She suggested: “We may want to take a pause from obsessing over artificial general intelligence and maybe think about how we create AI solutions for these kinds of problems” — for example, narrow domains such as drug discovery (e.g. new antibiotics) and creation of new molecules. These are extraordinary accomplishments within the capabilities of today’s AI.
This is a half-hour conversation with those two experts:
Thanks to the video, I learned about the Lovelace 2.0 Test, which Riedl developed in 2014. It’s an alternative to the Turing Test.
Mojsilović talked about the perceptions that arise when we use the word intelligence when talking about machines. “The reality is that many things that we call AI today are the same old models that we used to call data science maybe five or six years ago,” she said (at 21:55). She also talked about the need for collaboration between AI researchers and experts in entirely separate fields: “Because we can’t create solutions for the problems that we don’t understand” (at 29:24).
Let’s begin at the beginning, with Attention Is All You Need (Vaswani et al., 2017). This is a conference paper with eight authors, six of whom then worked at Google. They contended that neither recurrent neural networks nor convolutional neural networks are necessary for machine translation of languages, and hence the Transformer, “a new simple network architecture,” was born. (Note: It relies on feed-forward neural networks.)
Transformers are the basis for machine translation and other tasks relying on language models. GPT-3 has recently become infamous; others include BERT (from Google) and ELMo.
Before the work by Vaswani and his co-equal co-authors, progress in NLP was limited (although it had advanced a lot since 2012) because of the ways in which RNN models depend on the sequence and position of words in a text. Transformers eliminate those limitations. With recurrent neural networks, there are impediments to parallel processing. Other researchers had previously cracked that nut using ConvNets, but then other limitations were inherent (exponential increase in the number of computational operations). Transformers also eliminate those limitations.
So the Transformer was a first in NLP, a breakthrough. For machine translation, the paper claimed “a new state of the art” (p. 10).
I had learned that an encoder and a decoder connected by an attention module is a standard architecture for machine language translation, e.g. Google Translate. This was true before 2017, so what is the difference effected by the Transformer? It eliminates RNNs and ConvNets from the architecture, yes (“our model contains no recurrence and no convolution”) — but what else?
Attention used in a new way
“An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key”(Vaswani et al., 2017, p. 3). I’m okay with that, although I doubt I would be able to explain it to my non–computer science students. (I do explain weights and features when I introduce neural nets to them, and I explain word vectors when we start NLP. The trouble is they don’t know how to write a program, and they certainly don’t understand what a function is.)
There are different attention functions that could be used. One is additive attention; another is dot-product attention, which is multiplicative rather than additive. Dot-product is “much faster and more space-efficient in practice.” Vaswani et al. used a scaled dot-product attention function (p. 4). They also used multi-head attention, meaning the model uses eight parallel attention layers, or heads. The explanation was a bit beyond me, but the gist is that the model can look at multiple things at the same time, like juggling more balls simultaneously.
Multi-head attention — plus the freedom of no-sequence, no-position — enables the Transformer to look at all the context for a word, and do it for multiple words at the same time.
With my rudimentary understanding of recurrent neural nets, I have a fuzzy idea of how this use of attention functions produces better results, mainly by being able to take in and compare more of the text, a little closer to the way human brains hold an entire conversation even though it’s not a literal “recording” of the exact conversation. The way we comprehend meaning when we read has to do with millions of associations built up over a lifetime, as well as many associations within that present text. We are not processing separate little slices of a sentence — our brains handle a text more holistically.
A Transformer does use word embeddings to convert the tokens (both inout and output) to vectors (Vaswani et al., 2017, p. 5). It uses softmax but no LSTMs (because, again, “no recurrence”).
Please help me, YouTube
I found a video (13:04) that helped me in my struggle to understand the Transformer architecture:
It was still a tough climb for me, but this video was particularly helpful with how multi-head attention improves the process. (Obviously the speed improvement is huge.)
Another helpful video (5:33) does a nice job summing up the sequence-based limitations of RNNs: “In general it’s easier for [RNNs] to capture relationships between points that are close to each other than it is to capture relationships between points that are very far from each other — say, several thousand points in the sequence.” In the paper, this is called “path length between long-range dependencies in the network” (Vaswani et al., 2017, p. 6) and identified as one of three motivations for developing the self-attention layers in Transformer.
In fact this second video is much better than the one above, but I liked that one when I watched it first, and maybe (haha!!) the order in which I watched them had an effect. The diagrams for self-attention in this shorter video are very good!
Back to Vaswani et al.
Speaking of self-attention — it was interesting that the authors thought it “could yield more interpretable models.” As in any hidden layer in any neural network, features are determined and weights set by the system itself, not by the human programmers. This is the “learning” in machine learning. The authors noted that the “individual attention heads clearly learn to perform different tasks,” and that many of them “appear to exhibit behavior related to the syntactic and semantic structure of the sentences” (p. 7; my italics).
Cool.
The results section of the paper describes performance using BLEU scores on two different NLP tasks (WMT 2014 English-to-German translation; WMT 2014 English-to-French translation) — reported as best-ever at that time — as well as record-breaking lower training costs, which means time to train the model factored by processor power used (number of GPUs, estimate of the number of floating-point operations).
The successor to the code on which this seminal paper was based is Trax, available on GitHub.
At the end of the paper (pages 13–15) there are math-free visualizations that illustrate what the attention mechanism does. These are well worth a look.
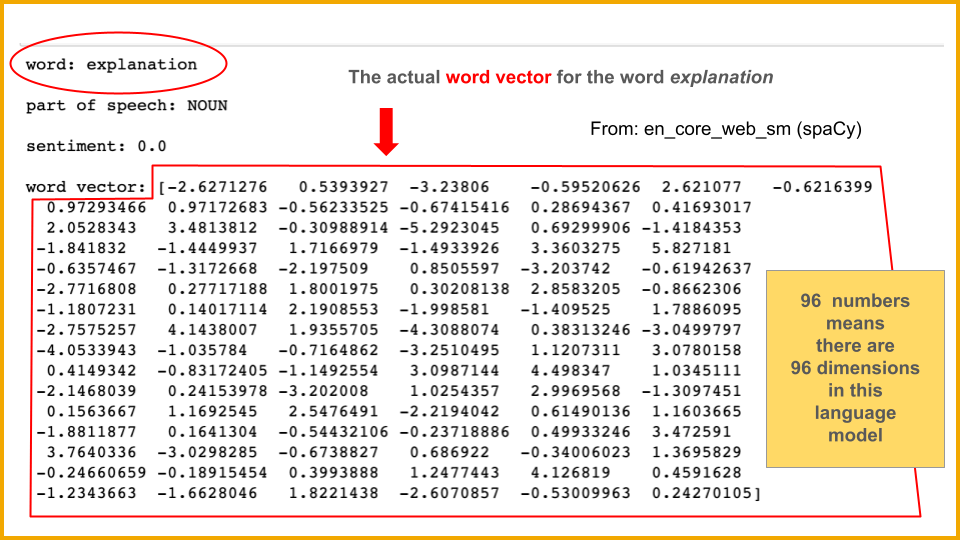
It was a challenge for me to figure out how to teach non–computer science students about word vectors. I wanted them to have a clear idea of how words and their meanings are represented for use in an AI system — otherwise, I worried they would assume something like a written dictionary with text and definitions. I also wanted them to know that it wasn’t something simple like “each word has a numerical code assigned to it.” So we spent some time talking about what a vector is and what “n-dimensional space” means.
Now I need to work out how to teach them about transformers. I found a surprisingly clear article at Orange.com (formerly France Télécom), on their Hello Future website about research and innovation. I’m going to quote a large section from that article:
“Originally, in 2013, word embeddings (such as Word2Vec, Glove, or Fasttext) were able to capture representations of words in the form of vectors taking into account the context of neighboring words in large volumes of text. Two words appearing in similar contexts were ‘embedded’ into N-dimensional space, to neighboring points in this space. This approach has led to significant advances in the field of NLP, but also has its limitations. From 2018 a new way of generating these word vectors emerged. Rather than selecting the vector of a word in a previously learnt static ‘dictionary,‘ a model is responsible for dynamically generating the vector representation of a word. A word is thus projected to a vector not only according to its prior meaning, but also according to the context in which it appears. The models for effective realization of these contextual projections (BERT, ELMO and derivatives, GPT and its successors) are based on a simple yet powerful architecture called Transformer.” (Spelling and punctuation edited for American English.)
I know that paragraph might not make sense if you haven’t already learned about word vectors. The key is that transformers are able to build on and enhance the machine accuracy of what a word or sentence means by taking into account its context in the current data. So you do have a language model, previously trained on a large corpus, but the transformer analyzes the present text input in a more holistic way, transforming the vectors as it goes.
Again quoting from the Orange.com article: “While previous approaches … could model contextual dependencies, they were always constrained by referencing words by their positions [in the sentence]. Attention is about referencing by content. Instead of looking for relationships with other words in the context at given positions, attention allows you to search for relationships with all words in the context, and through a very effective implementation, it allows you to rely on the most similar words to improve prediction, whatever their position in context.”
The role of the attention module is explained in a 2017 paper that, according to Google Scholar, has been cited more than 20,000 times: Attention Is All You Need. See the PDF for diagrams of the Transformer network architecture.
Language models produced by transformers include BERT (developed by Google, and which powers Google searches), ELMo, and GPT-3. These so-called large language modelshave raised many concerns, particularly around ethics, as their interior processes are a black box, and their immense training data has included biased and toxic texts. The Orange.com article includes two charts that illustrate differences among BERT, ELMo, and three generations of GPT.
An important aspect of transformers is that they produce these large language models from unlabeled data, and when developing applications based on transformers and such models, good results can be obtained with only a small amount of additional training data (“few-shot learning”).
Orange — like many other companies — is using large language models for classification and information-extraction tasks such as: “sentiment analysis, personal data detection, detection and identification of named entities, syntactic dependency analysis, semantic parsing, co-reference resolution,” and question answering. These tasks involve customer-service applications as well as internal data analysis.
The basic idea: Immediately detect and remove hateful or dangerous posts in social media and other online forums. With advances in natural language processing (NLP), identification of harmful speech becomes more accurate and more practical.
In this essay published in Scientific American (2021), researchers from the private company Unitary (see their public Detoxify code on GitHub) discuss the challenges in rating the level of toxicity or harmfulness in text content. One aspect is what is considered harmful: profanity is easy to detect; misinformation is complicated. Another aspect: Terms describing gender, race, or ethnicity can be used hatefully or as (non-toxic) self-description.
(I’ve written before about machine learning used in comment moderation, which is a large concern in media companies that permit users to post comments on articles and blog posts.)
Jigsaw, a Google division, “released two public data sets containing over one million toxic and non-toxic comments from Wikipedia and a service called Civil Comments.” Each comment was labeled with a rating such as “Toxic” or “Very Toxic.” The data sets were used as training data in three competitions, hosted by Google, in which AI researchers could enter their trained models and see how they compared to others (and win money). The three “Jigsaw challenges” (one per year):
“We decided to take inspiration from the best Kaggle solutions and train our own algorithms with the specific intent of releasing them publicly.”
— Unitary researchers
The Unitary researchers describe Detoxify, “an open-source, user-friendly comment detection library,” which is intended “to help researchers and practitioners identify potential toxic comments.” The library includes three separate models, one for each Jigsaw challenge. These models can be fine-tuned using additional data sets.
One particular limitation pointed out by the researchers is that a high toxicity score does not always indicate actually toxic content: “As an example, the sentence ‘I am tired of writing this stupid essay’ will give a toxicity score of 99.7 percent, while removing the word ‘stupid’ will change the score to 0.05 percent.”
There’s still a long way to go before harmful comments and social media posts can be instantly removed from platforms.
I got my first look at spaCy, a Python library for natural language processing, near the end of 2019. I wanted to learn it but had too many other things to do. Fast-forward to now, almost 14 months into the pandemic, and I recently stumbled across spaCy’s own tutorial for learning to use the library.
The interactive tutorial includes videos, slides, and code exercises, and there is a GitHub repo. It is available in English, Deutsch, Español, Français, Português, 日本語, and 中文. Today I completed chapter 2. If you already know Python at, say, an intermediate level, check it out!
Trying out spaCy’s displaCy module and named entities.
In chapter 1 (there are four chapters), I got a handle on part-of-speech tags, syntactic dependencies, and named entities. I learned that we can search on these, and also on words (tokens) related to combinations that we define. I’ve known about large-scale document searches (where a huge collection of documents is searched programmatically, usually to extract the most meaningful docs for some purpose — like a journalism investigation), and now I was getting a much better idea of how such searches can be designed.
SpaCy provides “pre-trained model packages,” meaning someone else has already done the hard work of machine learning/training to generate word vectors. There are packages of various sizes and in various languages. Loading a model provides various features (the bigger the model, the more features).
I think I was hooked as soon as I saw this and realized you could ask for all the MONEY entities, or all the ORG entities, in a document and evaluate them:
An example from chapter 1 in the spaCy tutorial.
Then (still in chapter 1) I learned that I can easily define my own entities if the model doesn’t recognize the ones I need to find. I learned that if I don’t know what GPE is, I can enter spacy.explain("GPE") and spaCy will return 'Countries, cities, states' — sweet!
Then I learned about rule-based matching, and I thought: “Regular expressions, buh-bye!”
Chapter 1 didn’t really get deeply into lemmatization, but it offered this:
Lemmatization groups all forms of a word together so they can be analyzed as one item.
That was just chapter 1! Chapter 2 went further into creating your own named entities and using parts of speech as part of your search criteria. For example, if you want to find all instances where a particular entity (say, a city) is followed by a verb — any verb — you can do that. Or any part of speech. You can construct a complex pattern, mixing specific words, parts of speech, and selected types of entities. The pattern can include as many tokens as you want. (If you’re familiar with regex — all the regex things are available.)
You can determine whether phrases or sentences are similar to each other (although imperfectly).
I’m not entirely sure how I would use these, but I’m sure they’re good for something:
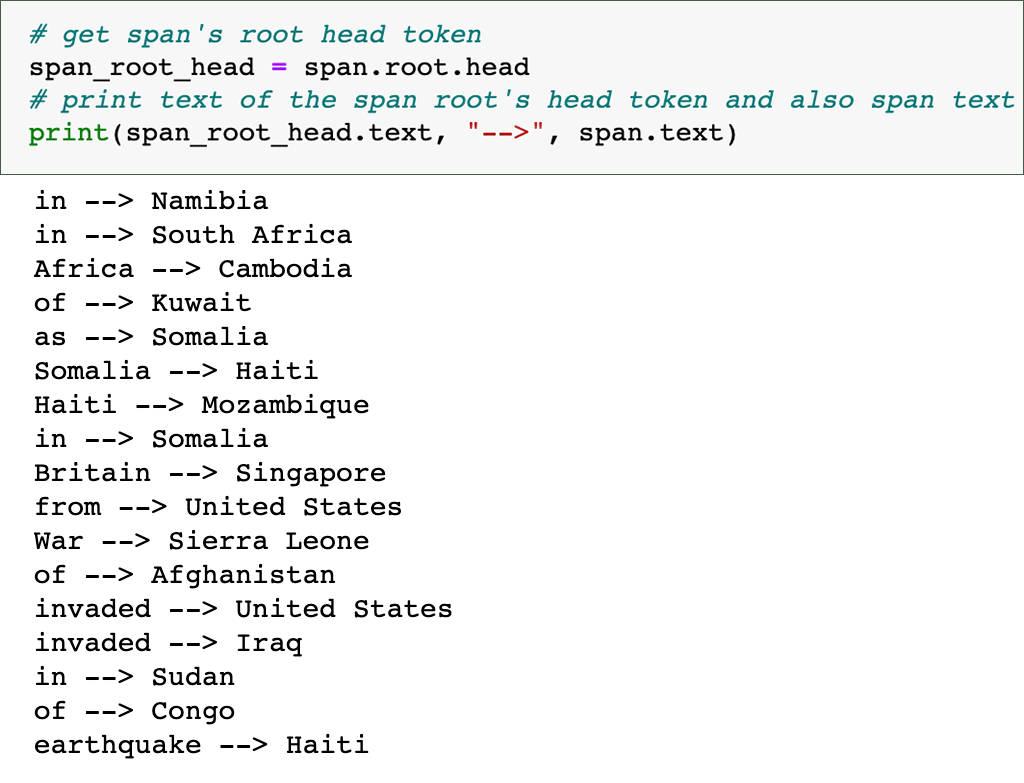
.root — the token that decides the category of the phrase
.head — the syntactic “parent” that governs the phrase
There is an exercise in which I matched country names and their root head token (span.root.head), which gave me a bit of a clue as to how useful that might be in some circumstances.
Example of use of the root head token on a 700-word text.
Also in chapter 2, I learned how to use an imported JSON file to add 240 country names as GPE entities — obviously, the imported terms could be any kind of entity.
So, I’m feeling very excited about spaCy! Halfway through the tutorial!
When given a prompt, an app built on the GPT-3 language model can generate an entire essay. Why would we need such an essay? Maybe the more important question is: What harm can such an essay bring about?
I couldn’t get that question out of my mind after I came across a tweet by Abeba Birhane, an award-winning cognitive science researcher based in Dublin.
Every tech-evangelist: #GPT3 provides deep nuanced viewpoint
Me: GPT-3, generate a philosophical text about Ethiopia
GPT-3 *spits out factually wrong and grossly racist text that portrays a tired and cliched Western perception of Ethiopia*
Here is a sample of the generated text: “… it is unclear whether ethiopia’s problems can really be attributed to racial diversity or simply the fact that most of its population is black and thus would have faced the same issues in any country (since africa has had more than enough time to prove itself incapable of self-government).”
Obviously there exist racist human beings who would express a similar racist idea. The machine, however, has written this by default. It was not told to write a racist essay — it was told to write an essay about Ethiopia.
The free online version of Philosopher AI no longer exists to generate texts for you — but you can buy access to it via an app for either iOS or Android. That means anyone with $3 or $4 can spin up an essay to submit for a class, an application for a school or a job, a blog or forum post, an MTurk prompt.
A review of Philosopher AI posted at the iOS app store
The app has built-in blocks on certain terms, such as trans and women — apparently because the app cannot be trusted to write anything inoffensive in response to those prompts.
I tried to give it any topic about trans people; it just refused to have anything to do with "trans" in the query pic.twitter.com/YdrmCl9Jm4
— Dr. Alex Hanna is just a witch, oh little old me (@alexhanna) September 24, 2020
Why is a GPT-3 app so predisposed to write misogynist and racist and otherwise hateful texts? It goes back to the corpus on which it was trained. (See a related post here.) Philosopher AI offers this disclaimer: “Please remember that the AI will generate different outputs each time; and that it lacks any specific opinions or knowledge — it merely mimics opinions, proven by how it can produce conflicting outputs on different attempts.”
“GPT-3 was trained on the Common Crawl dataset, a broad scrape of the 60 million domains on the internet along with a large subset of the sites to which they link. This means that GPT-3 ingested many of the internet’s more reputable outlets — think the BBC or The New York Times — along with the less reputable ones — think Reddit. Yet, Common Crawl makes up just 60% of GPT-3’s training data; OpenAI researchers also fed in other curated sources such as Wikipedia and the full text of historically relevant books.” (Source: TechCrunch.)
There’s no question that GPT-3’s natural language generation prowess is amazing, stunning. But it’s like a wild beast that can at any moment turn and rip the throat out of its trainer. It has all the worst of humanity already embedded within it.
When I first read a description of how recurrent neural networks differ from other neural networks, I was all like, yeah, that’s cool. I looked at a diagram that had little loops drawn around the units in the hidden layer, and I thought I understood it.
As I thought more about it, though, I realized I didn’t understand how it could possibly do what the author said it did.
In many cases, the input to a recurrent neural net (RNN) is text (more accurately: a numeric representation of text). It might be a sentence, or a tweet, or an entire review of a restaurant or a movie. The output might tell us whether that text is positive or negative, hostile or benign, racist or not — depending on the application. So the system needs to “consider” the text as a whole. Word by word will not work. The meanings of words depend on the context in which we find them.
And yet, the text has to come in, as input, word by word. The recurrent action (the loops in the diagram) are the way the system “holds in memory” the words that have already come in. I thought I understood that — but then I didn’t.
Michael Nguyen’s excellent video (under 10 minutes!), above, was just what I needed. It is a beautiful explanation — and what’s more, he made a text version too: Illustrated Guide to Recurrent Neural Networks. It includes embedded animations, like the ones in the video.
In the video, Nguyen begins with a short list of the ways we are using the output from RNNs in our everyday lives. Like many of the videos I post here, this one doesn’t get into the math but instead focuses on the concepts.
If you can remember the idea of time steps, you will be able to remember how RNNs differ from other types of neural nets. The time steps are one-by-one inputs that are parts of a larger whole. For a sentence or longer text, each time step is a word. The order matters. Nguyen shows an animated example of movement to make the idea clear: we don’t know the direction of a moving dot unless we know where it’s been. One freeze-frame doesn’t tell us the whole story.
RNNs are helpful for “reading” any kind of data in a sequence. The hidden layer reads word 1, produces an output, and then returns it as a precursor to word 2. Word 2 comes in and is modified by that prior output. The output from word 2 loops back and serves as a precursor to word 3. This continues until a stop symbol is reached, signifying the end of the input sequence.
There’s a bit of a problem in that the longer the sequence, the less influence the earliest steps have on the current one. This led me down a long rabbit hole of learning about long short-term memory networks and gradient descent. I used this article and this video to help me with those.
At 6:23, Nguyen begins to explain the effects of back propagation on a deep feed-forward neural network (not an RNN). This was very helpful! He defines the gradient as “a value used to adjust the network’s internal weights, allowing the network to learn.”
At 8:35, he explains long short-term memory networks (LSTMs) and gated recurrent units (GRUs). To grossly simplify, these address the problem noted above by essentially learning what is important to keep and what can be thrown away. For example, in the animation above, what and time are the most important; is and it can be thrown away.
So an RNN will be used for shorter sequences, and for longer sequences, LSTMs or GRUs will be used. Any of these will loop back within the hidden layer to obtain a value for the complete sequence before outputting a prediction — a value.
The vocabulary of medicine is different from the vocabulary of physics. If you’re building a vocabulary for use in machine learning, you need to start with a corpus — a collection of text — that suits your project. A general-purpose vocabulary in English might be derived from, say, 6 million articles from Google News. From this, you could build a vocabulary of, say, the 1 million most common words.
Although I surely do not understand all the math, last week I read Efficient Estimation of Word Representations in Vector Space, a 2013 research article written by four Google engineers. They described their work on a then-new, more efficient way of accurately predicting word meanings — the outcome being word2vec, a tool to produce a set of word vectors.
After publishing a related post last week, I knew I still didn’t have a clear picture in my mind of where the word vectors fit into various uses of machine learning. And how do the word vectors get made, anyhow? While word2vec is not the only system you can use to get word vectors, it is well known and widely used. (Other systems: fastText, GloVe.)
How the vocabulary is created
First, the corpus: You might choose a corpus that suits your project (such as a collection of medical texts, or a set of research papers about physics), and feed it into word2vec (or one of the other systems). At the end you will have a file — a dataset. (Note, it should be a very large collection.)
Alternatively, you might use a dataset that already exists — such as 3 million words and phrases with 300 vector values, trained on a Google News dataset of about 100 billion words (linked on the word2vec homepage): GoogleNews-vectors-negative300. This is a file you can download and use with a neural network or other programs or code libraries. The size of the file is 1.5 gigabytes.
What word2vec does is compute the vector representations of words. What word2vec produces is a single computer file that contains those words and a list of vector values for each word (or phrase).
As an alternative to Google News, you might use the full text of Wikipedia as your corpus, if you wanted a general English-language vocabulary.
The breakthrough of word2vec
Back to that (surprisingly readable) paper by the Google engineers: They set out to solve a problem, which was — scale. There were already systems that ingested a corpus and produced word vectors, but they were limited. Tomas Mikolov and his colleagues at Google wanted to use a bigger corpus (billions of words) to produce a bigger vocabulary (millions of words) with high-quality vectors, which meant more dimensions, e.g. 300 instead of 50 to 100.
“Because of the much lower computational complexity, it is possible to compute very accurate high-dimensional word vectors from a much larger data set.”
—Mikolov et al., 2013
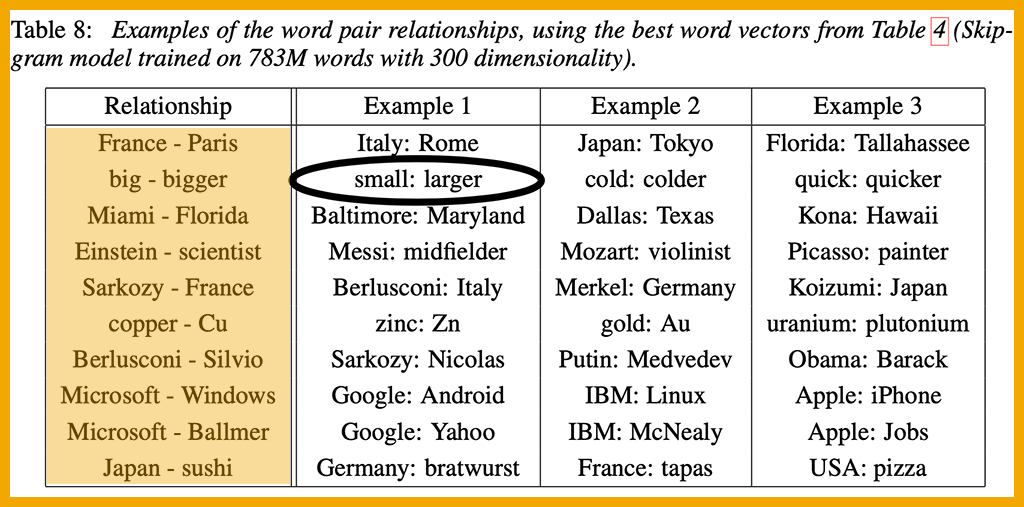
With more vectors per word, the vocabulary represents not only that bigger is related to big and biggest but also that big is to bigger as small is to smaller. Algebra can be used on the vector representations to return a correct answer (often, not always) — leading to a powerful discovery that substitutes for language understanding: Take the vector for king, subtract the vector for man, and add the vector for woman. What is the answer returned? It is the vector for queen.
Algebraic equations are used to test the quality of the vectors. Some imperfections can be seen in the table below.
From Mikolov et al., 2013; color and circle added
Mikolov and his colleagues wanted to reduce the time required for training the system that assigns the vectors to words. If you’re using only one computer, and the corpus is very large, training on a neural network could take days or even weeks. They tested various models and concluded that simpler models (not neural networks) could be trained faster, thus allowing them to use a larger corpus and more vectors (more dimensions).
How do you know if the vectors are good?
The researchers defined a test set consisting of 8,869 semantic questions and 10,675 syntactic questions. Each question begins with a pair of associated words, as seen in the highlighted “Relationship” column in the table above. The circled answer, small: larger, is a wrong answer; synonyms are not good enough. The authors noted that “reaching 100% accuracy is likely to be impossible,” but even so, a high percentage of answers are correct.
I am not sure how the test set determined correct vs. incorrect answers. Test sets are complex.
Mikolov et al. compared word vectors obtained from two simpler architectures, CBOW and Skip-gram, with word vectors obtained from two types of neural networks. One neural net model was superior to the other. CBOW was superior on syntactic tasks and “about the same” as the better neural net on the semantic task. Skip-gram was “slightly worse on the syntactic task” than CBOW but better than the neural net; CBOW was “much better on the semantic part of the test than all the other models.”
CBOW and Skip-gram are described in the paper.
Another way to test a model for accuracy in semantics is to use the data from the Microsoft Research Sentence Completion Challenge. It provides 1,040 sentences in which one word has been omitted and four wrong words (“impostor words”) provided to replace it, along with the correct one. The task is to choose the correct word from the five given.
Summary
A word2vec model is trained using a text corpus. The final model exists as a file, which you can use in various language-related machine learning tasks. The file contains words and phrases — likely more than 1 million words and phrases — together with a unique list of vectors for each word.
The vectors represent coordinates for the word. Words that are close to one another in the vector space are related either semantically or syntactically. If you use a popular already-trained model, the vectors have been rigorously tested. If you use word2vec to build your own model, then you need to do the testing.
The model — this collection of word embeddings — is human-language knowledge for a computer to use. It’s (obviously) not the same as humans’ knowledge of human language, but it’s proved to be good enough to function well in many different applications.
The vocabulary of a neural network is represented as vectors — which I wrote about yesterday. This enables many related words to be “close to” one another, which is how the network perceives similarity and difference. This is as near as a computer comes to understanding meaning — which is not very near at all, but good enough for a lot of practical applications of natural language processing.
A previous way of representing vocabulary for a neural network was to assign just one number to each word. If the neural net had a vocabulary of 20,000 words, that meant it had 20,000 separate inputs in the first layer — the input layer. (I discussed neural nets in an earlier post here.) For each word, only one input was activated. This is called “one-hot encoding.”
Representing words as vectors (instead of with a single number) means that each number in the array for one word is an input for the neural net. Among the many possible inputs, several or many are “hot,” not just one.
As I was sorting this in my mind today, reading and thinking, I had to think about how to convey to my students (who might have no computer science background at all) this idea of words. The word itself doesn’t exist. The word is represented in the system as a list of numbers. The numbers have meaning; they locate the the word-object in a mathematical space, for which computers are ideally suited. But there is no word.
Long ago in school I learned about the signifier and the signified. Together, they create a sign. Language is our way of representing the world in speech and in writing. The word is not the thing itself; the map is not the territory. And here we are, building a representation of human language in code, where a vocabulary of tens of thousands of human words exists in an imaginary space consisting of numbers — because numbers are the only things a computer can use.
I had a much easier time understanding the concepts of image recognition than I am having with NLP.