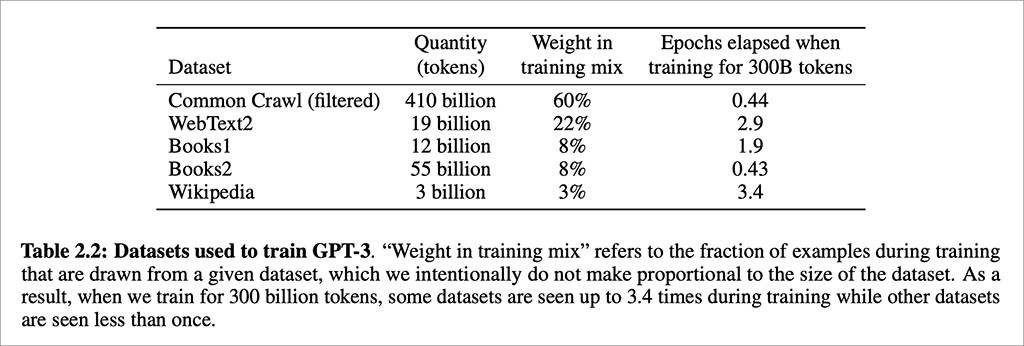
Because “artificial intelligence” and “AI” have become such potent buzzwords in business — and so many firms are trying to sell some kind of “AI” system or software or strategy to every business possible — we should all take a step back and evaluate whether there is actual AI operating in some of these systems.
That won’t always be easy to discern. If a company claims there is “AI” in its product, they are not going to divulge exactly how it works. If they want to convince you, their literature or their engineers will likely throw out a tangled net of terms that, while accurate, might not help anyone but another engineer understand what’s inside the black box.
I was thinking about this recently as I worked on assignments for an online computer science course in AI. One of the early projects was to program a tic-tac-toe game in which a human can play against “an AI.” Just like most humans, the AI can force a tie in every tic-tac-toe game unless the human makes a mistake, and then the human will lose. I wrote the code that enables the AI to play — that was the assignment. But I didn’t invent the code from nothing. I was taught in the course to use an algorithm called minimax. Further, I was encouraged to make my program faster by using another algorithm called alpha-beta pruning.
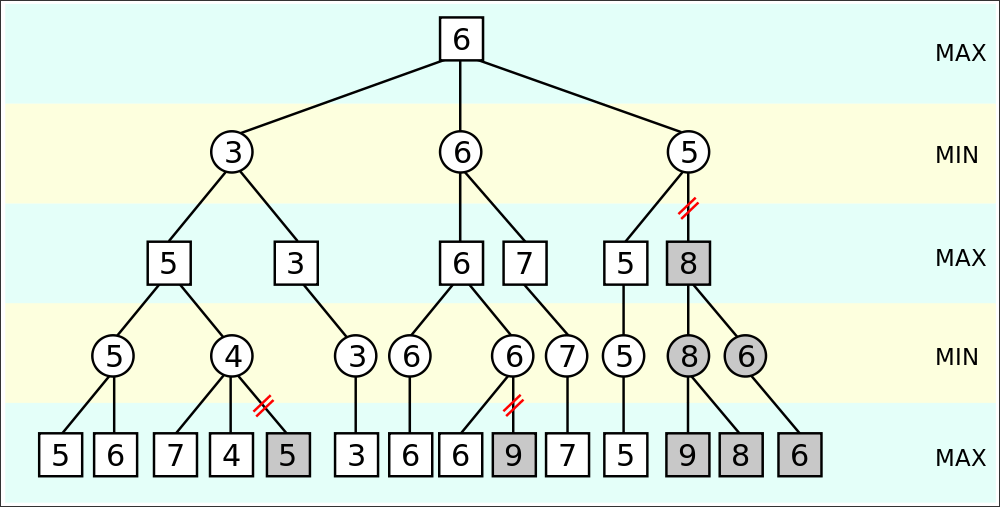
There is no machine learning involved in those two algorithms. They are simply a time-tested way for a computer language to direct a certain kind of look-ahead in a two-player game (not only tic-tac-toe).
Don’t despair or tune out — look at the diagram and understand that the computer, through instructions in my code, is able to rapidly advance through every possible outcome in tic-tac-toe and see how to: (a) prevent a win for the opponent, and (b) win if a win is possible.
There is no magic here.
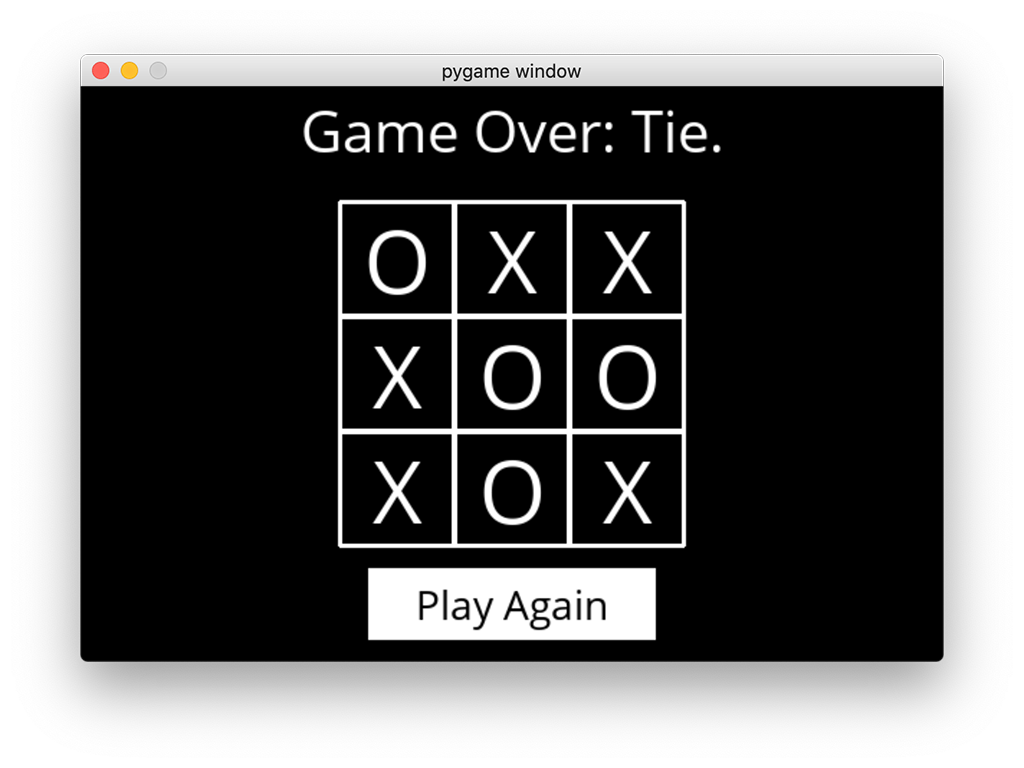
Another assignment in the same course has the students programming “an AI” that plays Minesweeper. This game is quite different from tic-tac-toe in that there is only one player, and there is hidden knowledge: The player doesn’t know where the mines are. One move at a time, the player builds knowledge about the game board.
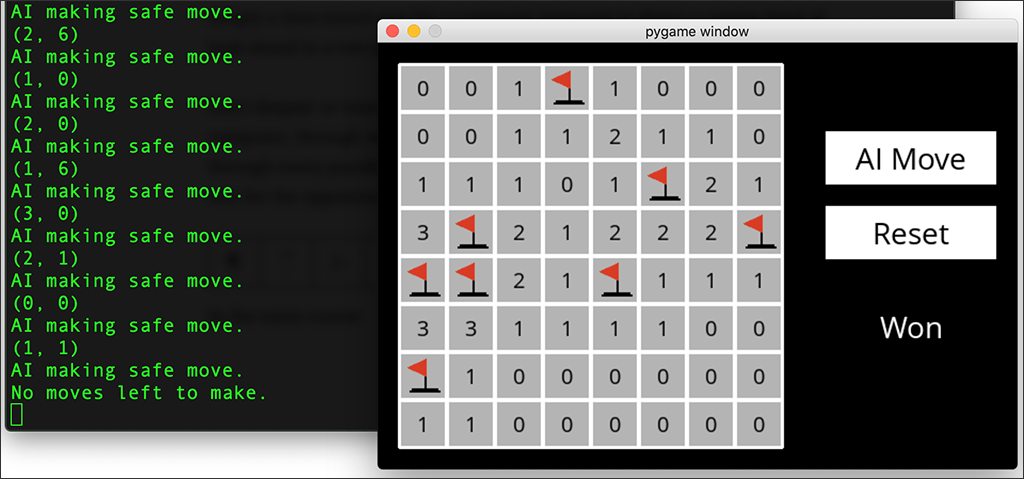
A human player doesn’t click on a mine, because she chooses squares that are next to a 0 (indicating no mines touch that square) and marks a mine square when it becomes obvious that a mine is hidden there.
The “AI” builds knowledge in a way that it is programmed to do (that is the assignment). In this case, there is no pre-existing algorithm, but there are principles of logic. I programmed “knowledge” that was stored in the program each time the AI clicked a square and a number was revealed. The knowledge is: (a) that number, and (b) the coordinates of all the surrounding squares. Thus the AI “knows” that, for example, among eight specified squares there are two mines.
If among eight specified squares there are zero mines, my code tells the AI to mark all eight of those squares as safe. My code also tells the AI that if there are any safe moves left to be made, then make a safe move. If not, make a random move. That is the only time when the AI can possibly set off a mine.
Once again, there is no magic here.
In contrast to these two simple examples of a computer successfully playing a game, AlphaGo (which I wrote about previously) uses real AI and could not have beaten a human Go master otherwise. Some games can’t be programmed with only simple algorithms or logic — if they are to win, they need something akin to intuition.
Programming a computer to develop and use an approximation of human intuition is what we have in today’s machine learning with deep neural networks. It’s still not magic, but it’s a lot more complicated than the kind of strictly mapped-out processes I wrote for playing tic-tac-toe or Minesweeper.

AI in Media and Society by Mindy McAdams is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Include the author’s name (Mindy McAdams) and a link to the original post in any reuse of this content.
.