Two new items related to educating the general public about artificial intelligence:
- The A–Z of AI: Making sense of artificial intelligence
- Helping students of all ages flourish in the era of artificial intelligence
The A–Z guide comes from the Oxford Internet Institute and Google. It’s slick, pretty, and animated. It consists of exactly 26 short items, one for each letter of the alphabet: artificial intelligence, bias, climate, datasets, ethics, fakes, etc. The aim is to provide answers in a not-overwhelming way.
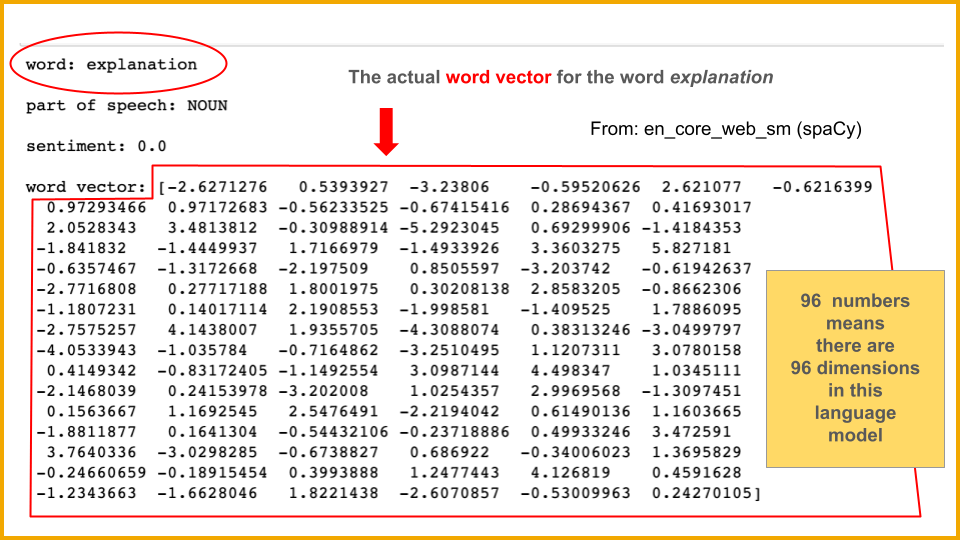
I love the idea, but I’m not in love with the execution. For example, the neural networks piece tells us that neural nets “attempt to mimic the structure of the brain,” but they “cannot ‘think’ like humans.” That’s great — clear and accurate. We could quibble about “attempt to mimic the structure,” but we can also let that slide. But then:
“AI design teams can assign each piece of a network to recognizing one of many characteristics. The sections of the network then work as one to build an understanding of the relationships and correlations between those elements — working out how they typically fit together and influence each other.”
To me, that seems misleading. It sounds as if the layers of the neural net are directed by specifically programmed instructions, but all my reading has indicated that the layers determine on their own which features they are detecting. (I’m thinking specifically about image recognition and supervised learning here.) This is important because it contributes to the “black box” problem of machine learning systems.
I also dislike phrases such as “build an understanding,” because that implies more intentionality than these networks actually have.
Giving people short, understandable explanations of specific aspects of AI is a wonderful idea, but the explanations need to be both straightforward and true.
The second education item I linked above comes from MIT’s news office. It describes a “new cross-disciplinary research initiative … to promote the understanding and use of AI across all segments of society.”
“People need to be AI-literate to understand the responsible use of AI and create things with it at individual, community, and societal levels.”
—Cynthia Breazeal, MIT professor, director of Responsible AI for Social Empowerment and Education (RAISE)
This sentiment is becoming more widely voiced as claims for the benefits of AI increase in the media. The idea behind RAISE is good and admirable — yes, people in all walks of life should have some understanding of AI, at least as much as they have an understanding of what makes airplanes fly and what makes computers able to store and retrieve our vacation photos.
Oh, wait.
In the United States, the average person’s understanding of any process involving physics or electronics might not be very good. Many students with stellar high-school grades don’t have a solid grasp of how their laptops or phones work at a basic level. I’m not talking about the students who attend MIT, but I am talking about those who can manage high SAT scores and gain admission to top public universities.
The RAISE initiative has identified four strategic areas for research, education, and outreach:
- Diversity and inclusion in AI
- AI literacy in pre-K–12 education
- AI workforce training
- AI-supported learning
But let’s go back to the A–Z guide and look at the segment about binary code, Zeros & Ones. It tells us that 0’s and 1’s are “the foundational language of computers.” It tells us that a particular long sequence of 0’s and 1’s means “Hello” to a computer. In one sense, that is true — but it really explains nothing to a layman. A computer system doesn’t know what “Hello” is (or means) any more than a rock does.
To accomplish AI literacy, we need to accomplish computer literacy. We need to teach and explain — clearly and accurately — to students at all levels what computers can and cannot do, how they are programmed, and how AI is different from, say, writing a game program that plays tic-tac-toe as well as any human can. I can write and run a winning tic-tac-toe program on an average laptop if I know which algorithms to use in my code — but there’s nothing remotely like intelligence in that program.
We need to add caveats every time we say something like “the computer learns,” or “the system understands.”
It will be fantastic if RAISE (and other outreach programs) can raise the level of computer literacy among Americans. It’s an important goal in this era of AI hype and euphoric claims, because it will be so much easier for people to be duped, exploited, mistreated, sidelined, marginalized, and/or denied jobs, loans, mortgages, healthcare, or admission to universities if they don’t understand what AI is and how it works.
.

AI in Media and Society by Mindy McAdams is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Include the author’s name (Mindy McAdams) and a link to the original post in any reuse of this content.
.