A common use of machine learning is to train a model to identify a particular kind of document, or a particular characteristic in a document — and then sort a gigantic set of documents. This produces a much-reduced subset of all documents that match the desired criteria. There might be some false positives in the subset, but it still gives researchers or journalists a big jump forward by eliminating thousands of unwanted documents.
This kind of sorting goes well beyond a simple search for keywords.
Above: Screenshot from On the Books at lib.unc.edu
There is a public GitHub repo of the code used in this project. It includes a full walkthrough of the project’s workflow — data acquisition and cleaning, OCR, unsupervised and supervised classification, etc.
The base document set (the main corpus) consists of 96 volumes, with 53,515 chapters, having 297,790 sections (source).
“State-based racial segregation laws were incredibly inconvenient, irregular, and, most importantly, unconstitutional.”
—William Sturkey, Ph.D.
A historical perspective on this data collection was provided by William Sturkey, a history professor at UNC, in “On the Books”: Machine Learning Jim Crow (September 2020). He says On the Books is “the first and most complete collection of all Jim Crow laws from a single American state.” He points to the difficulty of cataloging and studying all Jim Crow laws from any state “because there were just so many.”
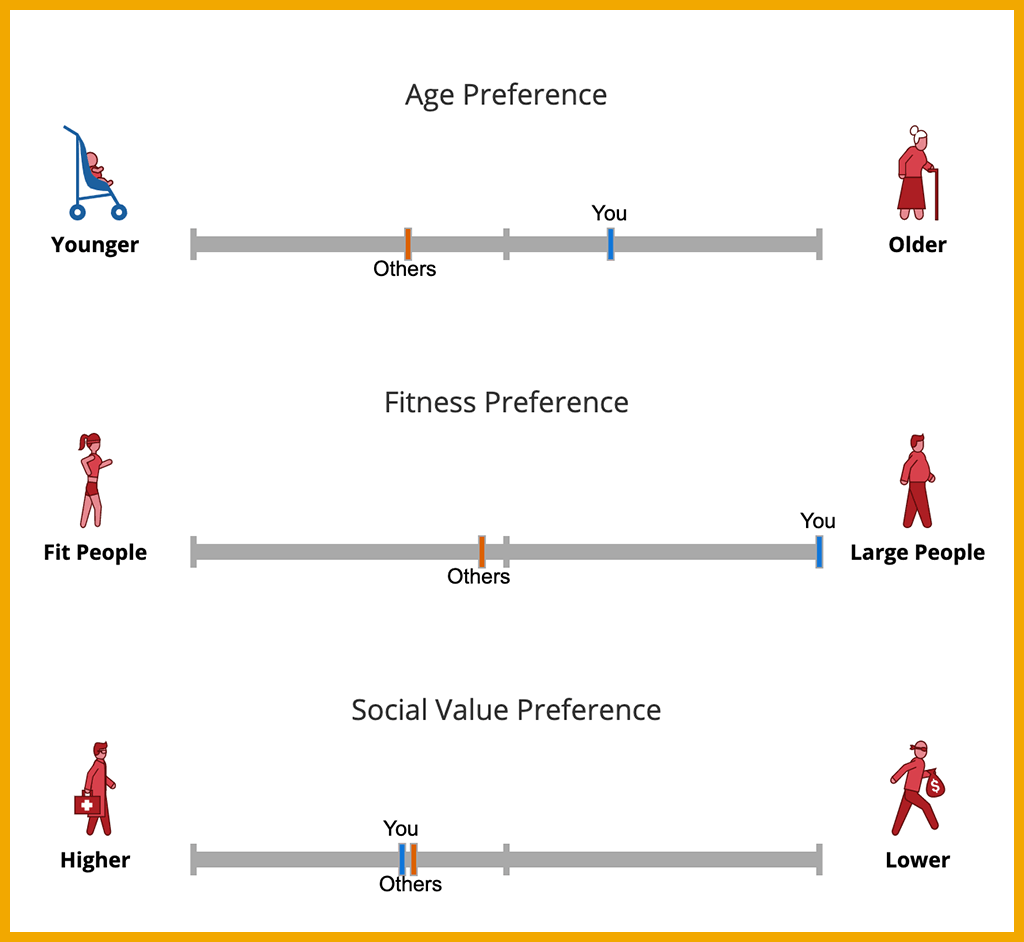
MIT has a cool and easy-to-play game (okay, not really a game, but like a game) in which you get to choose what a self-driving car would do when facing an imminent crash situation.
Above: Results from one round of playing the MoralMachine
At the end of one round, you get to see how your moral choices measure up to those of other people who have played. Note that all the drawings of people in the game have distinct meanings. People inside the car are also represented. Try it yourself here.
It is often discussed how the split-second decision affecting who lives, who dies is one of the most difficult aspects of training an autonomous vehicle.
Imagine this scenario:
“The car is programmed to sacrifice the driver and the occupants to preserve the lives of bystanders. Would you get into that car with your child?”
—Meredith Broussard, The Atlantic, 2018
In a 2018 article, Self-Driving Cars Still Don’t Know How to See, data journalist and professor Meredith Broussard tackled this question head-on. We find that the way the question is asked elicits different answers. If you say the driver might die, or be injured, if a child in the street is saved, people tend to respond: Save the child! But if someone says, “You are the driver,” the response tends to be: Save me.
You can see the conundrum. When programming the responses into the self-driving car, there’s not a lot of room for fine-grained moral reasoning. The car is going to decide in terms of (a) Is a crash is imminent? (b) What options exist? (c) Does any option endanger the car’s occupants? (d) Does any option endanger other humans?
In previous posts, I’ve written a little about the weights and probability calculations used in AI algorithms. For the machine, this all comes down to math. If (a) is True, then what options are possible? Each option has a weight. The largest weight wins. The prediction of the “best outcome” is based on probabilities.
The most wonderful thing about YouTube is you can use it to learn just about anything.
One of the 10,000 annoying things about YouTube is finding a good, satisfying version of the lesson you want to learn can take hours of searching. This is especially true of videos about technical aspects of machine learning. Of course there are one- and two-hour recordings of course lectures by computer science professors. But I’ve been seeking out shorter videos with more animations and illustrations of concepts.
Understanding what a neural network is and how it processes data is necessary to demystifying machine learning. Data goes in, results come out — but in between is a “black box” consisting of code and hardware. It sort of works like a human brain, and yet, it really doesn’t.
So here at last is a painless, math-free video that walks us through a neural network. The particular example shown uses the MNIST dataset, which consists of 70,000 images of handwritten digits, 0–9. So the task being performed is the recognition of those digits. (This kind of system can be used to sort mail using postal codes, for example.)
What you’ll see is how the first layer (a vertical line of circles on the left side) represents the input. If each of the MNIST images is 28 pixels wide by 28 pixels high, then that first layer has to represent 784 pixels and each of their color values — which is a number. (One image is the input — only one at a time.)
The final vertical layer, all the way to right side, is the output of the neural network. In this example, the output tells us which digit was in the input — 0, 1, 2, etc. To see the value in this, go back to the mail-sorting idea. If a system can read postal codes, it recognizes several numbers and then transmits them to another system that “knows” which postal code goes to which geographical location. My letter gets sorted into the Florida bin and yours into the bin for your home.
In between the input and the output are the vertical “hidden” layers, and that’s where the real work gets done. In the video you’ll see that the number of circles — often called neurons, but they can also be called just units — in a hidden layer might well be less than the number of units in the input layer. The number of units in the output layer can also differ from the numbers in other layers.
Beautifully, during an animation, our teacher Grant Sanderson explains and shows that the weights exist not in or on the units (the “neurons”) but in fact in or on the connectionsbetween the units.
Okay, I lied a little. There is some math shown here. The weight assigned to the connection is multiplied by the value of the unit to the left. The results are all summed, for all left-side units, and that sum is assigned to the unit to the right (meaning the right side of that one connection).
The video bogs down just a bit between the Sigmoid squishification function and applying the bias, but all you really need to grasp is that the value of the right-side unit shows whether or not that little region of the image (in this case, it’s an image) has a significant difference. The math is there to determine if the color, the amount of color, is significant enough to count. And how much it should count.
I know — math, right?
But seriously, watch the video. It’s excellent.
“And that’s a lot to think about! With this hidden layer of 16 neurons, that’s a total of 784 times 16 weights, along with 16 biases. And all of that is just the connections from the first layer to the second.”
—Grant Sanderson, But what is a neural network? (video)
Sanderson doesn’t burden us with the details of the additional layers. Once you’ve seen the animations for that first step — from the input layer through the connections to the first hidden layer — you’ll have a real appreciation for what’s happening under the hood in a neural network.
In the final 6 minutes of this 19-minute video, you’ll also learn how the “learning” takes place in machine learning when a neural net is involved. All those weights and bias values? They are not determined by humans.
“Digging into what the weights and biases are doing is a good way to challenge your assumptions and really expose the full space of possible solutions.”
—Grant Sanderson, But what is a neural network? (video)
I confess it does get rather mathy at the end, but hang on through the parts that are beyond your personal math background and listen to what Sanderson is telling us. You can get a lot out of it even if the equation itself is like hieroglyphics to you.
The video content ends at 16:26, followed by the usual “subscribe to my channel” message. More info about Sanderson and his excellent videos is on his website, 3Blue1Brown.
Reading course descriptions and degree plans has helped me understand more about the fields of artificial intelligence and data science. I think some universities have whipped up a program in one of these hot fields of study just to put something on the books. It’s quite unfair to students if this is just a collection of existing courses and not a deliberate, well structured path to learning.
I came across this page from Northeastern University that attempts to explain the “difference” between artificial intelligence and machine learning. (I use those quotation marks because machine learning is a subset of artificial intelligence.) The university has two different master’s degree programs for artificial intelligence; neither one has “machine learning” in its name — but read on!
One of the two programs does not require a computer science undergraduate degree. It covers data science, robotics, and machine learning.
The other master’s program is for students who do have a background in computer science. It covers “robotic science and systems, natural language processing, machine learning, and special topics in artificial intelligence.”
I noticed that data science is in the program for those without a computer science background, while it’s not mentioned in the other program. This makes sense if we understand that data science and machine learning really go hand in hand nowadays. A data scientist likely will not develop any new machine learning systems, but she will almost certainly use machine learning to solve some problems. Training in statistics is necessary so that one can select the best algorithm for use in machining learning for solving a particular problem.
Graduates of the other program, with their prior experience in computer science, should be ready to break ground with new and original AI work. They are not going to analyze data for firms and organizations. Instead, they are going to develop new systems that handle data in new ways.
The distinction between these two degree programs highlights a point that perhaps a lot of people don’t yet understand: people (like journalists who have code experience) are training models — using machine learning systems through writing code to control them — and yet they are not people who create new machine learning systems.
Separately there are developers who create new AI software systems, and engineers who create new AI hardware systems. In other words, there are many different roles in the AI field.
Finally, there are so-called AI systems sold to banks and insurance companies, and many other types of firms, for which the people using the system do not write code at all. Using them requires data to be entered, and results are generated (such as whose insurance rates will go up next year). The workers who use these systems don’t write code any more than an accountant writes code. Moreover, they can’t explain how the system works — they need only know what goes in and what comes out.
Discussions about regulation of AI, and algorithms in general, often revolve around privacy and misuse of personal data. Protections against bias and unfair treatment are also part of this conversation.
In a recent article in Harvard Business Review, lawyer Andrew Burt (who might prefer to be called a “legal engineer”) wrote about using existing legal standards to guide efforts at ensuring fairness in AI–based systems. In the United States, these include the Equal Credit Opportunity Act, the Civil Rights Act, and the Fair Housing Act.
Burt emphasizes the danger of unintentional discrimination, which can arise from basing the “knowledge” in the system on past data. You might think it would make sense to train an AI to do things the way your business has done things in the past — but if that means denying loans disproportionately to people of color, then you’re baking discrimination right into the system.
Burt linked to a post on the Google AI Blog that in turn links to a GitHub repo for a set of code components called ML-fairness-gym. The resource lets developers build a simulation to explore potential long-term impacts of a machine learning decision system — such as one that would decide who gets a loan and who doesn’t.
In several cases, long-term analysis via simulations showed adverse unintended consequences that arose from decisions made by ML. These are detailed in a paper by Google researchers. We can see that determining the true outcomes of use of AI systems is not just a matter of feeding in the data and getting a reliable model to churn out yes/no decisions for a firm.
It makes me wonder about all the cheerleading and hype around “business solutions” offered by large firms such as Deloitte. Have those systems been tested for their long-term effects? Is there any guarantee of fairness toward the people whose lives will be affected by the AI system’s decisions?
And what is “fair,” anyway? Burt points out that statistical methods used to detect a disparate impact depend on human decisions about “what ‘fairness’ should mean in the context of each specific use case” — and also how to measure fairness.
The same applies to the law — not only in how it is written but also in how it is interpreted. Humans write the laws, and humans sit in judgment. However, legal standards are long established and can be used to place requirements on companies that produce, deploy, and use AI systems, Burt suggests.
Companies must “carefully monitor and document all their attempts to reduce algorithmic unfairness.”
They must also “generate clear, good faith justifications for using the models” that are at the heart of the AI systems they develop, use, or sell.
If these suggested standards were applied in a legal context, it could be shown whether a company had employed due diligence and acted responsibly. If the standards were written into law, companies that deploy unfair and discriminatory AI systems could be held liable and face penalties.
Continuing my summary of the lessons in Introduction to Machine Learning from the Google News Initiative, today I’m looking at Lesson 5 of 8, “Training your Machine Learning model.” Previous lessons were covered here and here.
Now we get into the real “how it works” details — but still without looking at any code or computer languages.
The “lesson” (actually just a text) covers a common case for news organizations: comment moderation. If you permit people to comment on articles on your site, machine learning can be used to identify offensive comments and flag them so that human editors can review them.
With supervised learning (one of three approaches included in machine learning; see previous post here), you need labeled data. In this case, that means complete comments — real ones — that have already been labeled by humans as offensive or not. You need an equally large number of both kinds of comments. Creating this dataset of comments is discussed more fully in the lesson.
You will also need to choose a machine learning algorithm. Comments are text, obviously, so you’ll select among the existing algorithms that process language (rather than those that handle images and video). There are many from which to choose. As the lesson comes from Google, it suggests you use a Google algorithm.
In all AI courses and training modules I’ve looked at, this step is boiled down to “Here, we’ll use this one,” without providing a comparison of the options available. This is something I would expect an experienced ML practitioner to be able to explain — why are they using X algorithm instead of Y algorithm for this particular job? Certainly there are reasons why one text-analysis algorithm might be better for analyzing comments on news articles than another one.
What is the algorithm doing? It is creating and refining a model. The more accurate the final model is, the better it will be at predicting whether a comment is offensive. Note that the model doesn’t actually know anything. It is a computer’s representation of a “world” of comments in which some — with particular features or attributes perceived in the training data — are rated as offensive, and others — which lack a sufficient quantity of those features or attributes — are rated as not likely to be offensive.
The lesson goes on to discuss false positives and false negatives, which are possibly unavoidable — but the fewer, the better. We especially want to eliminate false negatives, which are offensive comments not flagged by the system.
“The most common reason for bias creeping in is when your training data isn’t truly representative of the population that your model is making predictions on.”
—Lesson 6, Bias in Machine Learning
Lesson 6 in the course covers bias in machine learning. A quick way to understand how ML systems come to be biased is to consider the comment-moderation example above. What if the labeled data (real comments) included a lot of comments offensive to women — but all of the labels were created by a team of men, with no women on the team? Surely the men would miss some offensive comments that women team members would have caught. The training data are flawed because a significant number of comments are labeled incorrectly.
There’s a pretty good video attached to this lesson. It’s only 2.5 minutes, and it illustrates interaction bias, latent bias, and selection bias.
Lesson 6 also includes a list of questions you should ask to help you recognize potential bias in your dataset.
It was interesting to me that the lesson omits a discussion of how the accuracy of labels is really just as important as having representative data for training and testing in supervised learning. This issue is covered in ImageNet and labels for data, an earlier post here.
The separation of machine learning into three different approaches — supervised learning, unsupervised learning, and reinforcement learning — is standard (Lesson 3). In keeping with the course’s focus on journalism applications of ML, the example given for supervised learning is The Atlanta Journal-Constitution‘s deservedly famous investigative story about sex abuse of patients by doctors. Supervised learning was used to sort more than 100,000 disciplinary reports on doctors.
The example of unsupervised learning is one I hadn’t seen before. It’s an investigation of short-term rentals (such as Airbnb rentals) in Austin, Texas. The investigator used locality-sensitive hashing (LSH) to group property records in a set of about 1 million documents, looking for instances of tax evasion.
The main example given for reinforcement learning is AlphaGo (previously covered in this blog), but an example from The New York Times — How The New York Times Is Experimenting with Recommendation Algorithms — is also offered. Reinforcement learning is typically applied when a clear “reward” can be identified, which is why it’s useful in training an AI system to play a game (winning the game is a clear reward). It can also be used to train a physical robot to perform specified actions, such as pouring a liquid into a container without spilling any.
Also in Lesson 3, we find a very brief description of deep learning (it doesn’t mention layers and weights). and just a mention of neural networks.
“What you should retain from this lesson is fairly simple: Different problems require different solutions and different ML approaches to be tackled successfully.”
—Lesson 3, Different approaches to Machine Learning
Lesson 4, “How you can use Machine Learning,” might be the most useful in this set of eight lessons. Its content comes (with permission) from work done by Quartz AI Studio — specifically from the post How you’re feeling when machine learning might help, by the super-talented Jeremy B. Merrill.
The examples in this lesson are really good, so maybe you should just read it directly. You’ll learn about a variety of unusual stories that could only be told when journalists used machine learning to augment their reporting.
“Machine learning is not magic. You might even say that it can’t do anything you couldn’t do — if you just had a thousand tireless interns working for you.”
Note (added April 4, 2022): The two links above to Quartz AI Studio content have been updated. The original domain, qz-dot-ai, was given up when, at renewal time, the price of all dot-ai domains had skyrocketed. Unfortunately, all the images have been lost, according to a personal communication from Merrill.
I couldn’t resist dipping into this free course from the Google News Initiative, and what I found surprised me: eight short lessons that are available as PDFs.
The good news: The lessons are journalism-focused, and they provide a painless introduction to the subject. The bad news: This is not really a course or a class at all — although there is one quiz at the end. And you can get a certificate, for what it’s worth.
There’s a lot here that many journalists might not be aware of, and that’s a plus. You get a brief, clear description of Reuters’ News Tracer and Lynx Insight tools, both used in-house to help journalists discover new stories using social media or other data (Lesson 1). A report I recall hearing about — how automated real-estate stories brought significant new subscription revenue to a Swedish news publisher — is included in a quick summary of “robot reporting” (also Lesson 1).
Lesson 2 helpfully explains what machine learning is without getting into technical operations of the systems that do the “learning.” They don’t get into what training a model entails, but they make clear that once the model exists, it is used to make predictions. The predictions are not like what some tarot-card reader tells you but rather probability-based results that the model is able to produce, based on its prior training.
Noting that machine learning is a subset of the wider field called artificial intelligence is, of course, accurate. What is inaccurate is the definition “specific applications that use data to train a model to perform a given task independently and learn from experience.” They left out Q-learning, a type of reinforcement learning (a subset of machine learning), which does not use a model. It’s okay that they left it out, but they shouldn’t imply that all machine learning requires a trained model.
The explosion of machine learning and AI in the past 10 years is explained nicely and concisely in Lesson 2. The lesson also touches on misconceptions and confusion surrounding AI:
“The lack of an officially agreed definition, the legacy of science-fiction, and a general low level of literacy on AI-related topics are all contributing factors.”
—Lesson 2, Is Machine Learning the same thing as AI?
Two days ago, I came upon this newly published course from FastAI: Practical Deep Learning for Coders. I actually stumbled across it via a video on YouTube, which I’ve watched now, and it made me feel optimistic about the course. I’m in the middle of the CS50 AI course from Harvard, though, so I need to hold off on the FastAI course for now.
Above: Screenshot from FastAi course
The first video got me thinking.
First, they said (as many others have said) that Python is the main programming language used for machine learning today. (This makes me happy, as I know Python.) But I wonder whether there’s more to this claim than I’m aware of.
Second, they said PyTorch has superseded TensorFlow as the framework of choice for machine learning. They said PyTorch is “much easier to use and much more useful for researchers.”
“Within the last 12 months, the percentage of papers at major conferences that use PyTorch has gone from 20 percent to 80 percent and vice versa — those that use TensorFlow have gone from 80 percent to 20 percent.”
—Jeremy Howard, in the FastAI video “Lesson 1 – Deep Learning for Coders (2020)”
Note, I don’t know if this is true. But it caught my attention.
FastAI is a library “that sits on top of PyTorch,” they explain. They say it is “the most popular higher-level API for PyTorch,” and it removes a lot of the struggle necessary to get started with PyTorch.
This leads me back to the CS50 AI course. The CS50 phenomenon was documented in The New Yorkerin July 2020. One insanely popular course, Introduction to Computer Science, has spawned multiple follow-on courses, including the seven-module course about the principles of artificial intelligence in which I am currently enrolled (not for credit).
In the various online forums and Facebook groups devoted to CS50, you can see a lot of people asking whether they need to take the intro course prior to starting the AI course. Some of them admit they have never programmed before. They know nothing about coding. But they think they might take an AI programming course as their very first computer science course.
This is what I was thinking about as the speakers in the FastAI video both praised how easy FastAI makes it to train a model and cautioned that machine learning is not a task for code newbies.
Training and testing a machine learning system — a system that will make predictions to be used in some industry, some social context, where human lives might be affected — should not be dependent on someone who learned how to do it in one online course.