
The vocabulary of medicine is different from the vocabulary of physics. If you’re building a vocabulary for use in machine learning, you need to start with a corpus — a collection of text — that suits your project. A general-purpose vocabulary in English might be derived from, say, 6 million articles from Google News. From this, you could build a vocabulary of, say, the 1 million most common words.
Although I surely do not understand all the math, last week I read Efficient Estimation of Word Representations in Vector Space, a 2013 research article written by four Google engineers. They described their work on a then-new, more efficient way of accurately predicting word meanings — the outcome being word2vec, a tool to produce a set of word vectors.
After publishing a related post last week, I knew I still didn’t have a clear picture in my mind of where the word vectors fit into various uses of machine learning. And how do the word vectors get made, anyhow? While word2vec is not the only system you can use to get word vectors, it is well known and widely used. (Other systems: fastText, GloVe.)
How the vocabulary is created
First, the corpus: You might choose a corpus that suits your project (such as a collection of medical texts, or a set of research papers about physics), and feed it into word2vec (or one of the other systems). At the end you will have a file — a dataset. (Note, it should be a very large collection.)
Alternatively, you might use a dataset that already exists — such as 3 million words and phrases with 300 vector values, trained on a Google News dataset of about 100 billion words (linked on the word2vec homepage): GoogleNews-vectors-negative300. This is a file you can download and use with a neural network or other programs or code libraries. The size of the file is 1.5 gigabytes.
What word2vec does is compute the vector representations of words. What word2vec produces is a single computer file that contains those words and a list of vector values for each word (or phrase).
As an alternative to Google News, you might use the full text of Wikipedia as your corpus, if you wanted a general English-language vocabulary.
The breakthrough of word2vec
Back to that (surprisingly readable) paper by the Google engineers: They set out to solve a problem, which was — scale. There were already systems that ingested a corpus and produced word vectors, but they were limited. Tomas Mikolov and his colleagues at Google wanted to use a bigger corpus (billions of words) to produce a bigger vocabulary (millions of words) with high-quality vectors, which meant more dimensions, e.g. 300 instead of 50 to 100.
“Because of the much lower computational complexity, it is possible to compute very accurate high-dimensional word vectors from a much larger data set.”
—Mikolov et al., 2013
With more vectors per word, the vocabulary represents not only that bigger is related to big and biggest but also that big is to bigger as small is to smaller. Algebra can be used on the vector representations to return a correct answer (often, not always) — leading to a powerful discovery that substitutes for language understanding: Take the vector for king, subtract the vector for man, and add the vector for woman. What is the answer returned? It is the vector for queen.
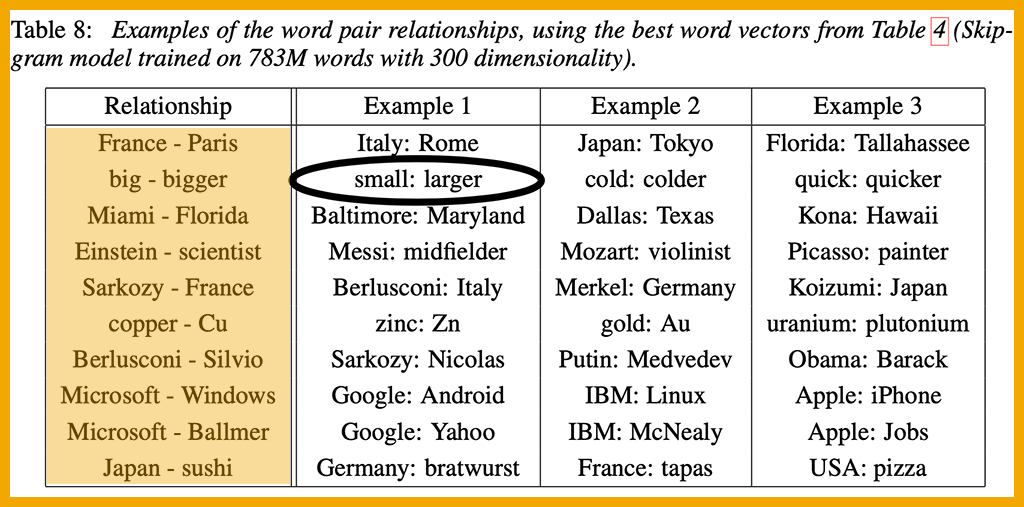
Algebraic equations are used to test the quality of the vectors. Some imperfections can be seen in the table below.
Mikolov and his colleagues wanted to reduce the time required for training the system that assigns the vectors to words. If you’re using only one computer, and the corpus is very large, training on a neural network could take days or even weeks. They tested various models and concluded that simpler models (not neural networks) could be trained faster, thus allowing them to use a larger corpus and more vectors (more dimensions).
How do you know if the vectors are good?
The researchers defined a test set consisting of 8,869 semantic questions and 10,675 syntactic questions. Each question begins with a pair of associated words, as seen in the highlighted “Relationship” column in the table above. The circled answer, small: larger, is a wrong answer; synonyms are not good enough. The authors noted that “reaching 100% accuracy is likely to be impossible,” but even so, a high percentage of answers are correct.
I am not sure how the test set determined correct vs. incorrect answers. Test sets are complex.
Mikolov et al. compared word vectors obtained from two simpler architectures, CBOW and Skip-gram, with word vectors obtained from two types of neural networks. One neural net model was superior to the other. CBOW was superior on syntactic tasks and “about the same” as the better neural net on the semantic task. Skip-gram was “slightly worse on the syntactic task” than CBOW but better than the neural net; CBOW was “much better on the semantic part of the test than all the other models.”
CBOW and Skip-gram are described in the paper.
Another way to test a model for accuracy in semantics is to use the data from the Microsoft Research Sentence Completion Challenge. It provides 1,040 sentences in which one word has been omitted and four wrong words (“impostor words”) provided to replace it, along with the correct one. The task is to choose the correct word from the five given.
Summary
A word2vec model is trained using a text corpus. The final model exists as a file, which you can use in various language-related machine learning tasks. The file contains words and phrases — likely more than 1 million words and phrases — together with a unique list of vectors for each word.
The vectors represent coordinates for the word. Words that are close to one another in the vector space are related either semantically or syntactically. If you use a popular already-trained model, the vectors have been rigorously tested. If you use word2vec to build your own model, then you need to do the testing.
The model — this collection of word embeddings — is human-language knowledge for a computer to use. It’s (obviously) not the same as humans’ knowledge of human language, but it’s proved to be good enough to function well in many different applications.

AI in Media and Society by Mindy McAdams is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Include the author’s name (Mindy McAdams) and a link to the original post in any reuse of this content.
.





