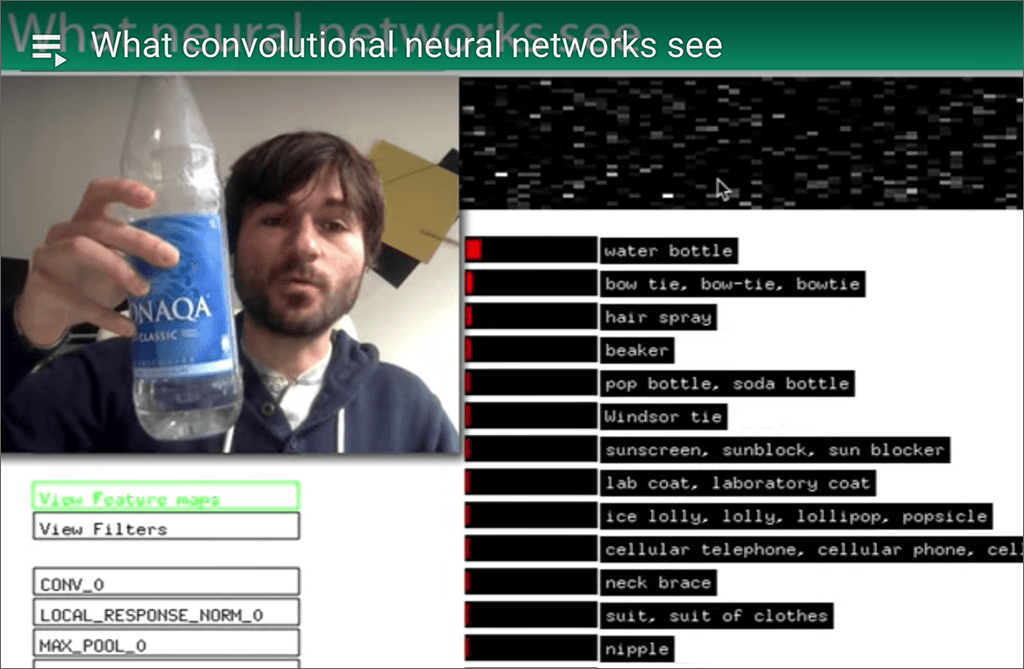
Think of a robot. Do you picture a human-looking construct? Does it have a human-like face? Does it have two legs and two arms? Does it have a head? Does it walk?
It’s easy to assume that a robot that walks across a room and picks something up has AI operating inside it. What’s often obscured in viral videos is how much a human controller is directing the actions of the robot.
I am a gigantic fan of the Spot videos from Boston Dynamics. Spot is not the only robot the company makes, but for me it is the most interesting. The video above is only 2 minutes long, and if you’ve never seen Spot in action, it will blow your mind.
But how much “intelligence” is built into Spot?
The answer lies in between “very little” and “Spot is fully autonomous.” To be clear, Spot is not autonomous. You can’t just take him out of the box, turn him on, and say, “Spot, fetch that red object over there.” (I’m not sure Spot can be trained to respond to voice commands at all. But maybe?) Voice commands aside, though, Spot can be programmed to perform certain tasks in certain ways and to walk from one given location to another.
This need for additional programming doesn’t mean that Spot lacks AI, and I think Spot provides a nice opportunity to think about rule-based programming and the more flexible reinforcement-learning type of AI.
This 20-minute video from Adam Savage (of MythBusters fame) gives us a look behind the scenes that clarifies how much of what we see in a video about a robot is caused by a human operator with a joystick in hand. If you pay attention, though, you’ll hear Savage point out what Spot can do that is outside the human’s commands.
Two points in particular stand out for me. The first is that when Spot falls over, or is upside-down, he “knows” how to make himself get right-side-up again. The human doesn’t need to tell Spot he’s upside-down. Spot’s programming recognizes his inoperable position and corrects it. Watching him move his four slender legs to do so, I feel slightly creeped out. I’m also awed by it.
Given the many incorrect positions in which Spot might land, there’s no way to program this get-right-side-up procedure using set, spelled-out rules. Spot must be able to use estimations in this process — just like AlphaGo did when playing a human Go master.
The second point, which Savage demonstrates explicitly, is accounting for non-standard terrain. One of the practical uses for a robot would be to send it somewhere a human cannot safely go, such as inside a bombed-out building — which would require the robot to walk over heaps of rubble and avoid craters. The human operator doesn’t need to tell Spot anything about craters or obstacles. The instruction is “Go to this location,” and Spot’s AI figures out how to go up or down stairs or place its feet between or on uneven surfaces.
The final idea to think about here is how the training of a robot’s AI takes place. Reinforcement learning requires many, many iterations, or attempts. Possibly millions. Possibly more than that. It would take lifetimes to run through all those training episodes with an actual, physical robot.
So, simulations. Here again we see how super-fast computer hardware, with multiple processes running in parallel, must exist for this work to be done. Before Spot — the actual robot — could be tested, he existed as a virtual system inside a machine, learning over nearly endless iterations how not to fall down — and when he did fall, how to stand back up.
See more robot videos on Boston Dynamics’ YouTube channel.

AI in Media and Society by Mindy McAdams is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Include the author’s name (Mindy McAdams) and a link to the original post in any reuse of this content.
.