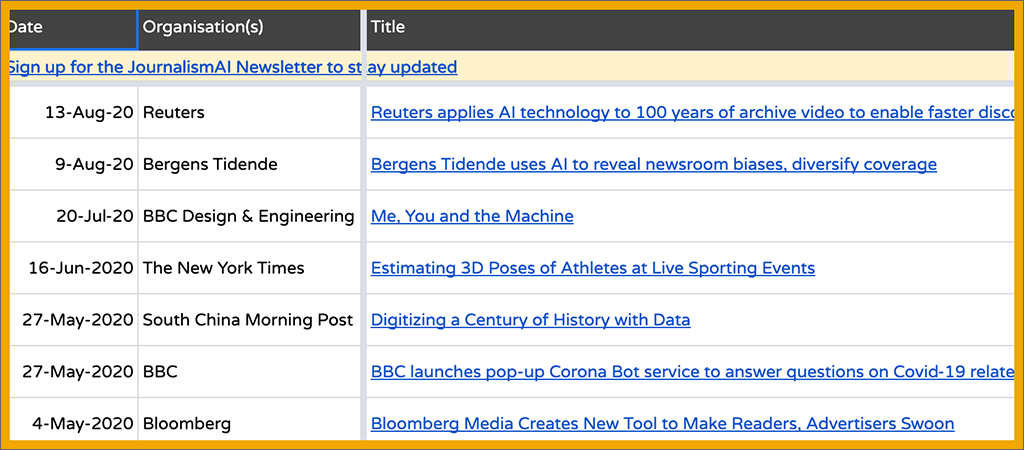
For Friday AI Fun, I’m sharing one of the first videos I ever watched about artificial intelligence. It’s a 10-minute TED Talk by Janelle Shane, and it’s actually pretty funny. I do mean “funny ha-ha.”
I’m not wild about the ice-cream-flavors example she starts out with, because what does an AI know about ice cream, anyway? It’s got no tongue. It’s got no taste buds.
But starting at 2:07, she shows illustrations and animations of what an AI does in a simulation when it is instructed to go from point A to point B. For a robot with legs, you can imagine it walking, yes? Well, watch the video to see what really happens.
This brings up something I’ve only recently begun to appreciate: The results of an AI doing something may be entirely satisfactory — but the manner in which it produces those results is very unlike the way a human would do it. With both machine vision and game playing, I’ve seen how utterly un-human the hidden processes are. This doesn’t scare me, but it does make me wonder about how our human future will change as we rely more on these un-human ways of solving problems.
“When you’re working with AI, it’s less like working with another human and a lot more like working with some kind of weird force of nature.”
—Janelle Shane
At 6:23 in the video, Shane shows another example that I really love. It shows the attributes (in a photo) that an image recognition system decided to use when identifying a particular species of fish. You or I would look at the tail, the fins, the head — yes? Check out what the AI looks for.
Shane has a new book, You Look Like a Thing and I Love You: How Artificial Intelligence Works and Why It’s Making the World a Weirder Place. I haven’t read it yet. Have you?

AI in Media and Society by Mindy McAdams is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Include the author’s name (Mindy McAdams) and a link to the original post in any reuse of this content.
.